> ## Documentation Index
> Fetch the complete documentation index at: https://docs.together.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# DeepSeek V4 Pro quickstart
> Call DeepSeek V4 Pro on Together for hybrid reasoning, long-context, and tool-using workloads.
DeepSeek V4 Pro is DeepSeek's frontier 1.6T-parameter Mixture-of-Experts model (49B active per token), with a hybrid attention architecture built for long-context, low-cost reasoning. On Together AI, it runs in FP4 with a 512K-token context window and supports streaming, function calling, structured outputs, and adjustable reasoning effort.
The model ID is `deepseek-ai/DeepSeek-V4-Pro`. Pricing is \$2.10 per 1M input tokens, \$4.40 per 1M output tokens, and \$0.20 per 1M cached input tokens.
## Quickstart
Reasoning is on by default, so most calls work with no extra configuration. Stream the response, since reasoning output can be long.
```python Python theme={null}
from together import Together
client = Together()
stream = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=[
{
"role": "user",
"content": "Prove that the square root of 2 is irrational.",
}
],
stream=True,
)
for chunk in stream:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
if hasattr(delta, "reasoning") and delta.reasoning:
print(delta.reasoning, end="", flush=True)
if hasattr(delta, "content") and delta.content:
print(delta.content, end="", flush=True)
```
```typescript TypeScript theme={null}
import Together from "together-ai";
const together = new Together();
const stream = await together.chat.completions.stream({
model: "deepseek-ai/DeepSeek-V4-Pro",
messages: [
{ role: "user", content: "Prove that the square root of 2 is irrational." },
],
});
for await (const chunk of stream) {
const delta = chunk.choices[0]?.delta;
if (delta?.reasoning) process.stdout.write(delta.reasoning);
if (delta?.content) process.stdout.write(delta.content);
}
```
```bash cURL theme={null}
curl -X POST "https://api.together.ai/v1/chat/completions" \
-H "Authorization: Bearer $TOGETHER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-V4-Pro",
"messages": [
{"role": "user", "content": "Prove that the square root of 2 is irrational."}
],
"stream": true
}'
```
The response separates the chain of thought from the final answer: reasoning tokens arrive in the `reasoning` field on each delta, and the answer arrives in `content`.
## Reasoning effort
DeepSeek V4 Pro accepts two effort levels through the `reasoning_effort` parameter:
* `"high"`: the default thinking depth. Use for most complex problems.
* `"max"`: maximum reasoning effort. Use for the hardest math, planning, and multi-step coding agents. Set the context window to at least 384K tokens for Think Max mode, and set `max_tokens` generously, since `"max"` mode can produce very long chains of thought.
Together normalizes other values automatically: `"low"` and `"medium"` map to `"high"`, and `"xhigh"` maps to `"max"`.
```python Python theme={null}
from together import Together
client = Together()
stream = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=[
{
"role": "user",
"content": "Find all integer solutions to x^3 + y^3 = z^3 + 1 with |x|,|y|,|z| <= 100.",
}
],
reasoning_effort="max",
temperature=1.0,
top_p=1.0,
max_tokens=384000,
stream=True,
)
for chunk in stream:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
if hasattr(delta, "reasoning") and delta.reasoning:
print(delta.reasoning, end="", flush=True)
if hasattr(delta, "content") and delta.content:
print(delta.content, end="", flush=True)
```
```typescript TypeScript theme={null}
import Together from "together-ai";
const together = new Together();
const stream = await together.chat.completions.stream({
model: "deepseek-ai/DeepSeek-V4-Pro",
messages: [
{
role: "user",
content:
"Find all integer solutions to x^3 + y^3 = z^3 + 1 with |x|,|y|,|z| <= 100.",
},
],
reasoning_effort: "max",
temperature: 1.0,
top_p: 1.0,
max_tokens: 384000,
});
for await (const chunk of stream) {
const delta = chunk.choices[0]?.delta;
if (delta?.reasoning) process.stdout.write(delta.reasoning);
if (delta?.content) process.stdout.write(delta.content);
}
```
For broader guidance on reasoning controls and prompting, see [Reasoning](/docs/inference/chat/reasoning).
## Long-context use
DeepSeek V4 Pro accepts up to 512K input tokens on Together. The model's hybrid attention combines Compressed Sparse Attention (CSA) with Heavily Compressed Attention (HCA), which keeps the key-value (KV) cache and per-token FLOPs roughly an order of magnitude smaller than DeepSeek V3.2 at long contexts.
Use the full context window with care. The model's ability to retrieve information is not uniform across the window, so refer to the needle-in-a-haystack results from [DeepSeek's paper](https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf) below.
For critical tasks, treat the first 256K of context as more reliable than the next 256K, and so on.
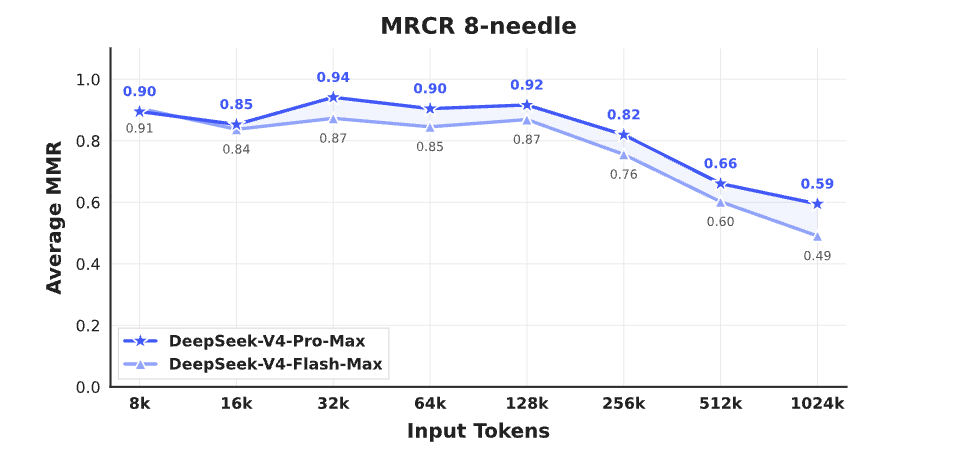 A few tips for long inputs:
* Put your instructions at the top of the prompt and your question at the bottom.
* Set `max_tokens` explicitly. Long contexts plus `reasoning_effort="max"` can produce very long completions.
## Recommended sampling parameters
DeepSeek recommends `temperature=1.0` and `top_p=1.0` for V4 Pro. Lower temperatures can collapse the reasoning trace and degrade answer quality, so prefer to control output length with `max_tokens` rather than turning down temperature.
## Reducing reasoning overhead
V4 Pro is a thinking-by-default hybrid model on Together. For simple turns where reasoning overhead is not needed, disable reasoning with `reasoning={"enabled": False}`:
```python theme={null}
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=[
{
"role": "user",
"content": "Translate 'good morning' into French.",
}
],
reasoning={"enabled": False},
max_tokens=512,
)
print(response.choices[0].message.content)
```
When you keep reasoning enabled, use `reasoning_effort="high"` (the default) and add a short instruction asking the model to keep its thinking concise.
## Multi-turn conversations
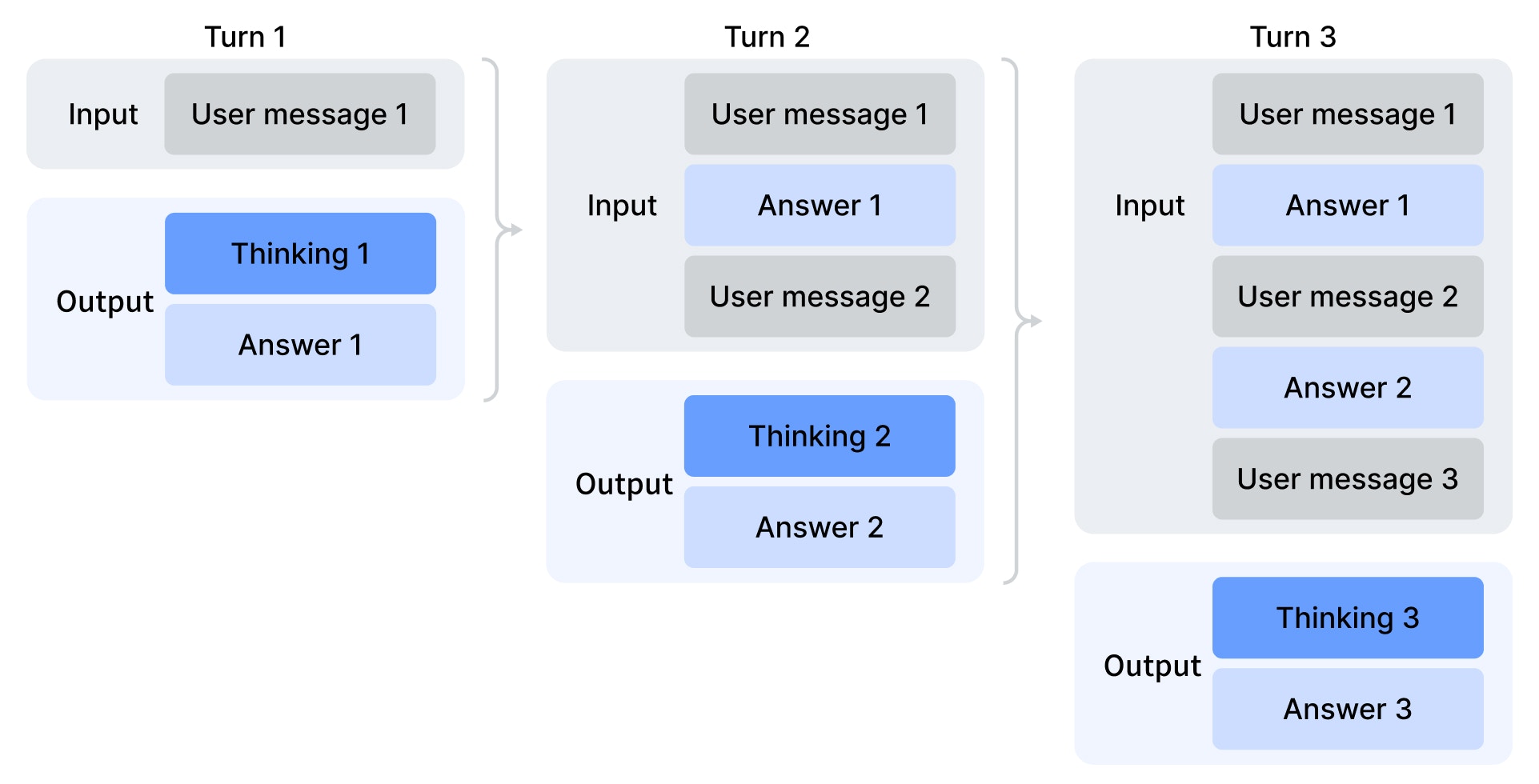
In each turn of the conversation, the model outputs both a chain-of-thought (`reasoning_content`) and a final answer (`content`). The API itself is stateless, so to continue a conversation, you must resend the prior `messages` for every request.
If the assistant's response included tool calls, pass both the previous answer and the CoT (`reasoning_content`) back in your next request to maintain the model's reasoning context. However, if there was **no tool call**, the prior CoT (`reasoning_content`) from previous turns is **not** included in the next turn's context. Only the usual conversation history carries forward. The diagram for multi-turn reasoning context illustrates this behavior:
A few tips for long inputs:
* Put your instructions at the top of the prompt and your question at the bottom.
* Set `max_tokens` explicitly. Long contexts plus `reasoning_effort="max"` can produce very long completions.
## Recommended sampling parameters
DeepSeek recommends `temperature=1.0` and `top_p=1.0` for V4 Pro. Lower temperatures can collapse the reasoning trace and degrade answer quality, so prefer to control output length with `max_tokens` rather than turning down temperature.
## Reducing reasoning overhead
V4 Pro is a thinking-by-default hybrid model on Together. For simple turns where reasoning overhead is not needed, disable reasoning with `reasoning={"enabled": False}`:
```python theme={null}
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=[
{
"role": "user",
"content": "Translate 'good morning' into French.",
}
],
reasoning={"enabled": False},
max_tokens=512,
)
print(response.choices[0].message.content)
```
When you keep reasoning enabled, use `reasoning_effort="high"` (the default) and add a short instruction asking the model to keep its thinking concise.
## Multi-turn conversations
In each turn of the conversation, the model outputs both a chain-of-thought (`reasoning_content`) and a final answer (`content`). The API itself is stateless, so to continue a conversation, you must resend the prior `messages` for every request.
If the assistant's response included tool calls, pass both the previous answer and the CoT (`reasoning_content`) back in your next request to maintain the model's reasoning context. However, if there was **no tool call**, the prior CoT (`reasoning_content`) from previous turns is **not** included in the next turn's context. Only the usual conversation history carries forward. The diagram for multi-turn reasoning context illustrates this behavior:
 Code example:
```python theme={null}
from together import Together
client = Together()
messages = [
{
"role": "user",
"content": "What is the highest mountain in the United States?",
}
]
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=messages,
reasoning_effort="high",
)
assistant_message = response.choices[0].message
messages.append(
{
"role": "assistant",
"content": assistant_message.content,
}
)
messages.append({"role": "user", "content": "How tall is it?"})
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=messages,
reasoning_effort="high",
)
print(response.choices[0].message.content)
```
## Function calling and interleaved reasoning
DeepSeek V4 Pro supports tool calling. Define tools in the standard OpenAI-compatible schema and pass them via `tools`.
```python Python theme={null}
from together import Together
client = Together()
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a city.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name.",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
},
},
"required": ["location"],
},
},
}
]
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=[
{"role": "user", "content": "What's the weather in Paris and Tokyo?"}
],
tools=tools,
)
print(response.choices[0].message.tool_calls)
```
```typescript TypeScript theme={null}
import Together from "together-ai";
const together = new Together();
const tools = [
{
type: "function" as const,
function: {
name: "get_weather",
description: "Get the current weather for a city.",
parameters: {
type: "object",
properties: {
location: { type: "string", description: "City name." },
unit: { type: "string", enum: ["celsius", "fahrenheit"] },
},
required: ["location"],
},
},
},
];
const response = await together.chat.completions.create({
model: "deepseek-ai/DeepSeek-V4-Pro",
messages: [{ role: "user", content: "What's the weather in Paris and Tokyo?" }],
tools,
});
console.log(response.choices[0].message.tool_calls);
```
For multi-turn function calling, pass the assistant message's reasoning trace back in every later request. This preserves the model's reasoning across tool calls and user turns. Include the assistant message's `content`, `reasoning_content`, and `tool_calls`, then append each tool result with the matching `tool_call_id`, as illustrated in the multi-turn function-calling diagram.
Code example:
```python theme={null}
from together import Together
client = Together()
messages = [
{
"role": "user",
"content": "What is the highest mountain in the United States?",
}
]
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=messages,
reasoning_effort="high",
)
assistant_message = response.choices[0].message
messages.append(
{
"role": "assistant",
"content": assistant_message.content,
}
)
messages.append({"role": "user", "content": "How tall is it?"})
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=messages,
reasoning_effort="high",
)
print(response.choices[0].message.content)
```
## Function calling and interleaved reasoning
DeepSeek V4 Pro supports tool calling. Define tools in the standard OpenAI-compatible schema and pass them via `tools`.
```python Python theme={null}
from together import Together
client = Together()
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a city.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name.",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
},
},
"required": ["location"],
},
},
}
]
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=[
{"role": "user", "content": "What's the weather in Paris and Tokyo?"}
],
tools=tools,
)
print(response.choices[0].message.tool_calls)
```
```typescript TypeScript theme={null}
import Together from "together-ai";
const together = new Together();
const tools = [
{
type: "function" as const,
function: {
name: "get_weather",
description: "Get the current weather for a city.",
parameters: {
type: "object",
properties: {
location: { type: "string", description: "City name." },
unit: { type: "string", enum: ["celsius", "fahrenheit"] },
},
required: ["location"],
},
},
},
];
const response = await together.chat.completions.create({
model: "deepseek-ai/DeepSeek-V4-Pro",
messages: [{ role: "user", content: "What's the weather in Paris and Tokyo?" }],
tools,
});
console.log(response.choices[0].message.tool_calls);
```
For multi-turn function calling, pass the assistant message's reasoning trace back in every later request. This preserves the model's reasoning across tool calls and user turns. Include the assistant message's `content`, `reasoning_content`, and `tool_calls`, then append each tool result with the matching `tool_call_id`, as illustrated in the multi-turn function-calling diagram.
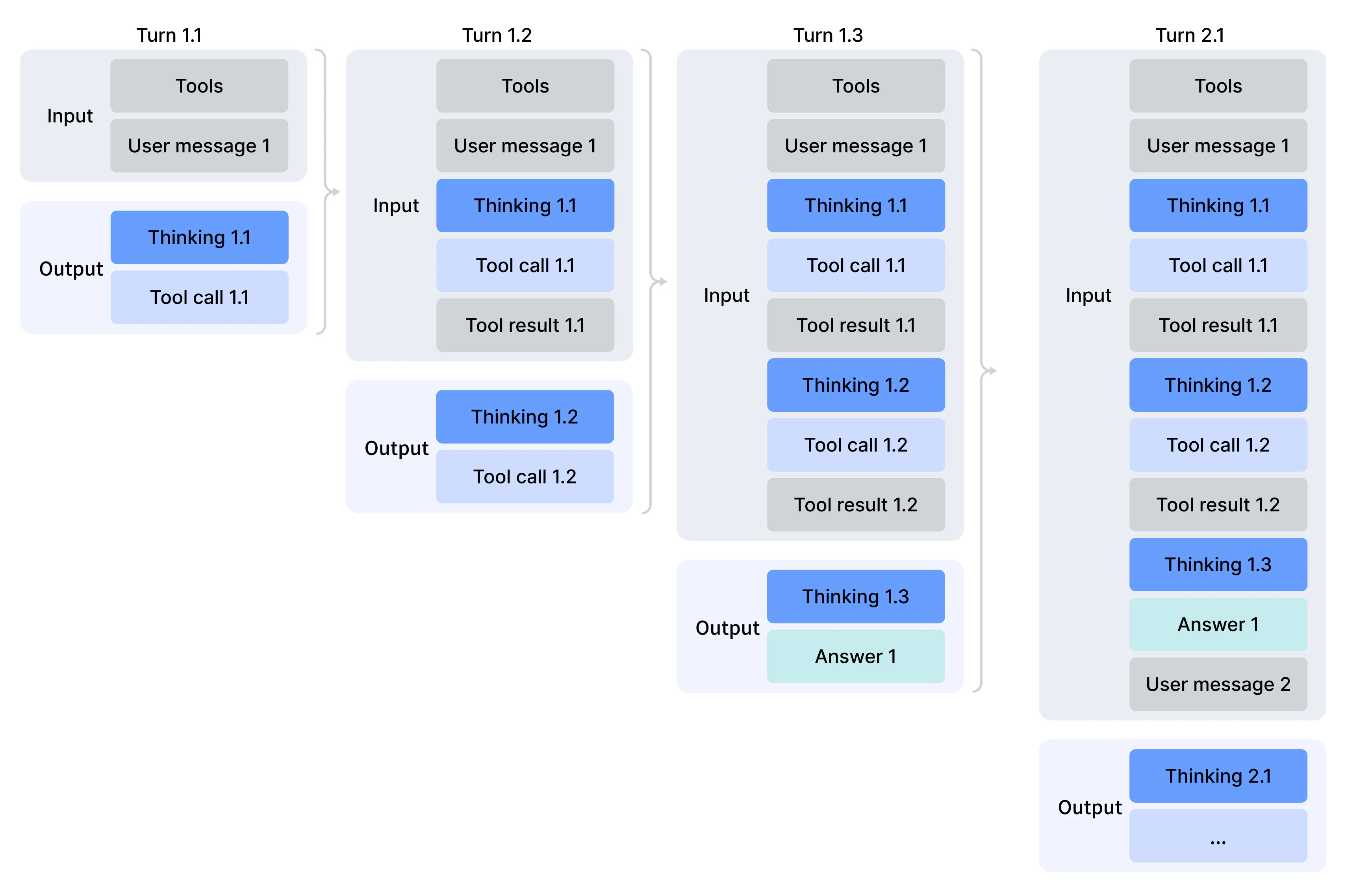 Code example:
```python theme={null}
import os
import json
from together import Together
from datetime import datetime
tools = [
{
"type": "function",
"function": {
"name": "get_date",
"description": "Get the current date",
"parameters": {"type": "object", "properties": {}},
},
},
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of a location, the user should supply the location and date.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name",
},
"date": {
"type": "string",
"description": "The date in format YYYY-mm-dd",
},
},
"required": ["location", "date"],
},
},
},
]
def get_date_mock():
return datetime.now().strftime("%Y-%m-%d")
def get_weather_mock(location, date):
return "Sunny 68~82°F"
TOOL_CALL_MAP = {
"get_date": get_date_mock,
"get_weather": get_weather_mock,
}
def run_turn(client, turn, messages):
sub_turn = 1
while True:
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=messages,
tools=tools,
reasoning_effort="high",
)
choice = response.choices[0].message
reasoning = getattr(choice, "reasoning", None) or getattr(
choice, "reasoning_content", None
)
content = choice.content
tool_calls = choice.tool_calls
print(f"Turn {turn}.{sub_turn}")
print(f" reasoning = {reasoning}")
print(f" content = {content}")
print(f" tool_calls= {tool_calls}")
assistant_msg = {
"role": "assistant",
"content": content or "",
}
if reasoning:
assistant_msg["reasoning_content"] = reasoning
if tool_calls:
assistant_msg["tool_calls"] = [
{
"id": tc.id,
"type": "function",
"function": {
"name": tc.function.name,
"arguments": tc.function.arguments,
},
}
for tc in tool_calls
]
messages.append(assistant_msg)
if not tool_calls:
break
for tool in tool_calls:
tool_function = TOOL_CALL_MAP[tool.function.name]
tool_result = tool_function(**json.loads(tool.function.arguments))
print(f" tool result for {tool.function.name}: {tool_result}")
messages.append(
{
"role": "tool",
"tool_call_id": tool.id,
"content": tool_result,
}
)
sub_turn += 1
print()
client = Together()
messages = [
{"role": "user", "content": "How's the weather in San Francisco tomorrow?"}
]
run_turn(client, 1, messages)
messages.append(
{"role": "user", "content": "How's the weather in New York tomorrow?"}
)
run_turn(client, 2, messages)
```
```text theme={null}
Turn 1.1
reasoning = The user wants to know the weather in San Francisco tomorrow. I need to get the current date first, and then use that to determine tomorrow's date. Then I'll call the weather function.
Let me start by getting the current date.
content =
tool_calls= [ToolChoice(id='call_02dbb9ade77b4e8890526e02', function=Function(arguments='{}', name='get_date'), index=0.0, type='function')]
tool result for get_date: 2026-04-29
Turn 1.2
reasoning = Today is 2026-04-29, so tomorrow is 2026-04-30. Now let me get the weather for San Francisco on that date.
content =
tool_calls= [ToolChoice(id='call_af2f753610ab4281a4ebe8ed', function=Function(arguments='{"location": "San Francisco", "date": "2026-04-30"}', name='get_weather'), index=1.0, type='function')]
tool result for get_weather: Sunny 68~82°F
Turn 1.3
reasoning = I have the weather information for San Francisco tomorrow. Let me summarize it for the user.
content = Tomorrow (April 30, 2026) in San Francisco is looking **sunny** with a temperature range of **68°F to 82°F** (about 20°C to 28°C). Should be a beautiful day — perfect for getting outside! ☀️
tool_calls= []
Turn 2.1
reasoning = The user wants the weather in New York tomorrow. I already know today is 2026-04-29, so tomorrow is 2026-04-30. Let me call the weather function directly.
content =
tool_calls= [ToolChoice(id='call_4c5c442c8f884f8bb09a2ad2', function=Function(arguments='{"location": "New York", "date": "2026-04-30"}', name='get_weather'), index=1.0, type='function')]
tool result for get_weather: Sunny 68~82°F
Turn 2.2
reasoning = The weather for New York tomorrow is the same as San Francisco in this case? That's what the tool returned. Let me present this to the user.
content = Tomorrow (April 30, 2026) in New York is also looking **sunny** with a high of **82°F** and a low of **68°F**. Looks like both coasts are getting great weather tomorrow! 🌞
tool_calls= []
```
Code example:
```python theme={null}
import os
import json
from together import Together
from datetime import datetime
tools = [
{
"type": "function",
"function": {
"name": "get_date",
"description": "Get the current date",
"parameters": {"type": "object", "properties": {}},
},
},
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of a location, the user should supply the location and date.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name",
},
"date": {
"type": "string",
"description": "The date in format YYYY-mm-dd",
},
},
"required": ["location", "date"],
},
},
},
]
def get_date_mock():
return datetime.now().strftime("%Y-%m-%d")
def get_weather_mock(location, date):
return "Sunny 68~82°F"
TOOL_CALL_MAP = {
"get_date": get_date_mock,
"get_weather": get_weather_mock,
}
def run_turn(client, turn, messages):
sub_turn = 1
while True:
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro",
messages=messages,
tools=tools,
reasoning_effort="high",
)
choice = response.choices[0].message
reasoning = getattr(choice, "reasoning", None) or getattr(
choice, "reasoning_content", None
)
content = choice.content
tool_calls = choice.tool_calls
print(f"Turn {turn}.{sub_turn}")
print(f" reasoning = {reasoning}")
print(f" content = {content}")
print(f" tool_calls= {tool_calls}")
assistant_msg = {
"role": "assistant",
"content": content or "",
}
if reasoning:
assistant_msg["reasoning_content"] = reasoning
if tool_calls:
assistant_msg["tool_calls"] = [
{
"id": tc.id,
"type": "function",
"function": {
"name": tc.function.name,
"arguments": tc.function.arguments,
},
}
for tc in tool_calls
]
messages.append(assistant_msg)
if not tool_calls:
break
for tool in tool_calls:
tool_function = TOOL_CALL_MAP[tool.function.name]
tool_result = tool_function(**json.loads(tool.function.arguments))
print(f" tool result for {tool.function.name}: {tool_result}")
messages.append(
{
"role": "tool",
"tool_call_id": tool.id,
"content": tool_result,
}
)
sub_turn += 1
print()
client = Together()
messages = [
{"role": "user", "content": "How's the weather in San Francisco tomorrow?"}
]
run_turn(client, 1, messages)
messages.append(
{"role": "user", "content": "How's the weather in New York tomorrow?"}
)
run_turn(client, 2, messages)
```
```text theme={null}
Turn 1.1
reasoning = The user wants to know the weather in San Francisco tomorrow. I need to get the current date first, and then use that to determine tomorrow's date. Then I'll call the weather function.
Let me start by getting the current date.
content =
tool_calls= [ToolChoice(id='call_02dbb9ade77b4e8890526e02', function=Function(arguments='{}', name='get_date'), index=0.0, type='function')]
tool result for get_date: 2026-04-29
Turn 1.2
reasoning = Today is 2026-04-29, so tomorrow is 2026-04-30. Now let me get the weather for San Francisco on that date.
content =
tool_calls= [ToolChoice(id='call_af2f753610ab4281a4ebe8ed', function=Function(arguments='{"location": "San Francisco", "date": "2026-04-30"}', name='get_weather'), index=1.0, type='function')]
tool result for get_weather: Sunny 68~82°F
Turn 1.3
reasoning = I have the weather information for San Francisco tomorrow. Let me summarize it for the user.
content = Tomorrow (April 30, 2026) in San Francisco is looking **sunny** with a temperature range of **68°F to 82°F** (about 20°C to 28°C). Should be a beautiful day — perfect for getting outside! ☀️
tool_calls= []
Turn 2.1
reasoning = The user wants the weather in New York tomorrow. I already know today is 2026-04-29, so tomorrow is 2026-04-30. Let me call the weather function directly.
content =
tool_calls= [ToolChoice(id='call_4c5c442c8f884f8bb09a2ad2', function=Function(arguments='{"location": "New York", "date": "2026-04-30"}', name='get_weather'), index=1.0, type='function')]
tool result for get_weather: Sunny 68~82°F
Turn 2.2
reasoning = The weather for New York tomorrow is the same as San Francisco in this case? That's what the tool returned. Let me present this to the user.
content = Tomorrow (April 30, 2026) in New York is also looking **sunny** with a high of **82°F** and a low of **68°F**. Looks like both coasts are getting great weather tomorrow! 🌞
tool_calls= []
```