> ## Documentation Index
> Fetch the complete documentation index at: https://docs.together.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Sprocket SDK
> A Python SDK for building inference workers that support both synchronous and asynchronous requests via Together's platform.
Sprocket is a Python SDK for building inference workers that run on Together's managed GPU infrastructure. You implement two methods — `setup()` and `predict()` — and Sprocket handles the HTTP server, queue integration, file transfers, health checks, and graceful shutdown.
**See Sprocket in action:** Check out our end-to-end examples for [Image Generation with Flux2](/docs/dedicated_containers_image) and [Video Generation with Wan 2.1](/docs/dedicated_containers_video).
Install Sprocket from Together's package index:
```shell pip theme={null}
pip install sprocket --extra-index-url https://pypi.together.ai/
```
```shell uv theme={null}
uv add sprocket --index https://pypi.together.ai/
```
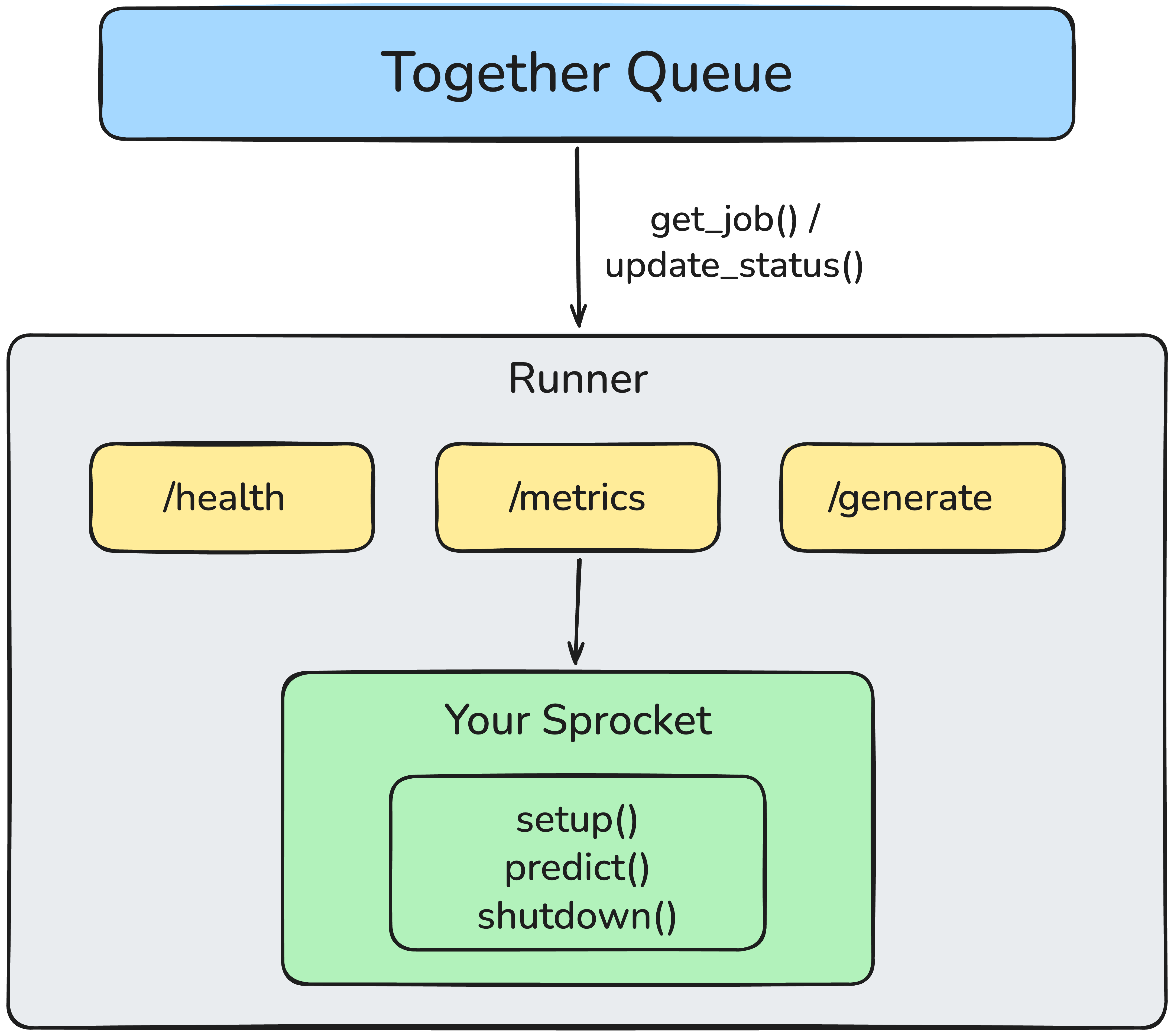
## How Sprocket Works
* **Model definition** — Subclass `Sprocket`, implement `setup()` to load your model and `predict(args) -> dict` to handle each request
* **Startup** — Calls `setup()` once, optionally runs warmup inputs for cache generation, then starts accepting traffic
* **HTTP endpoints** — `/health` for readiness checks, `/metrics` for autoscaler, `/generate` for direct HTTP inference
* **Job processing** — In queue mode, pulls jobs from Together's managed queue, downloads input URLs, calls `predict()`, uploads output files, and reports job status
* **Graceful shutdown** — On SIGTERM, finishes the current job, calls `shutdown()` for cleanup, and exits
* **Distributed inference** — With `use_torchrun=True`, launches one process per GPU and coordinates inputs/outputs across ranks
### Architecture
 ## File Handling
Sprocket automatically handles file transfers in both directions.
**Input files:** Any HTTPS URL in the job payload is downloaded to a local `inputs/` directory before `predict()` is called. The URL in the payload is replaced with the local file path, so your code just opens a local file. This works with Together's files API or any public URL.
**Output files:** Return a `FileOutput("path")` in your output dict and Sprocket uploads it to Together storage after `predict()` returns. The `FileOutput` is replaced with the public URL in the final job result.
**The full pipeline for each job is:**
1. Download input URLs → local files
2. Call `predict(args)` with local paths
3. Call `finalize()` on your `InputOutputProcessor` (if you've overridden it)
4. Upload any `FileOutput` values to Together storage
5. Report job result
**Custom I/O:** If you need to process downloaded files before they reach `predict()` (e.g., decompressing), or upload outputs to your own storage instead of Together's, you can subclass `InputOutputProcessor` and attach it to your Sprocket via the `processor` class attribute. See the [reference](/reference/dci-reference-sprocket#custom-io-processing) for the full API.
When using `use_torchrun=True` for multi-GPU inference, all file I/O (downloading inputs, uploading outputs, `finalize()`) runs in the parent process, not in the GPU worker processes. This keeps networking separate from GPU compute.
## Multi-GPU / Distributed Inference
For models that need multiple GPUs (tensor parallelism, context parallelism), pass `use_torchrun=True` to `sprocket.run()` and set `gpu_count` in your Jig config.
The architecture is:
* A **parent process** manages the HTTP server, queue polling, and file I/O
* `torchrun` launches **N child processes** (one per GPU), connected to the parent via a Unix socket
* For each job, the parent broadcasts inputs to all children, each child runs `predict()`, and the parent collects the output from whichever rank returns a non-None value (by convention, rank 0)
Your Sprocket code looks the same as single-GPU, with two additions: initialize `torch.distributed` in `setup()`, and return `None` from non-rank-0 processes:
```python Python theme={null}
import torch
import torch.distributed as dist
import sprocket
class DistributedModel(sprocket.Sprocket):
def setup(self):
dist.init_process_group()
torch.cuda.set_device(dist.get_rank())
self.model = load_and_parallelize_model()
def predict(self, args):
result = self.model.generate(args["prompt"])
if dist.get_rank() == 0:
result.save("output.mp4")
return {"url": sprocket.FileOutput("output.mp4")}
return None
if __name__ == "__main__":
sprocket.run(DistributedModel(), "my-org/my-model", use_torchrun=True)
```
```toml pyproject.toml theme={null}
[tool.jig.deploy]
gpu_type = "h100-80gb"
gpu_count = 4
```
## Error Handling
Sprocket distinguishes between **per-job errors** and **fatal errors**.
**Per-job errors:** If `predict()` raises an exception, the job is marked as `failed` with the error message, downloaded input files are cleaned up, and the worker moves on to the next job. The worker stays healthy — one bad input doesn't take down the whole deployment.
**Fatal errors** trigger a full worker restart (SIGTERM). These occur when:
* A prediction times out (torchrun mode only — exceeds `TERMINATION_GRACE_PERIOD_SECONDS`)
* A torchrun child process crashes or disconnects
* The connection to Together's API is lost
In torchrun mode, the job claim has a 90-second timeout that's refreshed every 45 seconds. If a worker dies mid-job, the queue reclaims the job and assigns it to another worker. In single-GPU mode, claims are held until completion with no timeout.
## Graceful Shutdown
When a container receives SIGTERM (during scale-down or redeployment):
1. Sprocket stops accepting new jobs
2. The current job runs to completion
3. Your `shutdown()` method is called for cleanup
4. The container exits
The total time allowed is controlled by `TERMINATION_GRACE_PERIOD_SECONDS` (default: 300s, configurable in `pyproject.toml`). Set this higher if your jobs are long-running — for example, video generation that takes several minutes per job.
## Running Modes
Sprocket supports two modes: **Queue mode** and **Request mode**.
* **Queue mode** is for workloads that need job durability and tracking — model generations, video rendering, or anything that takes more than a few hundred milliseconds. Jobs are persisted in the queue, survive worker restarts, and support priority ordering and progress reporting.
* **Request mode** (direct HTTP) is for low-latency workloads that don't need queueing — embedding inference, streaming voice models, or other "fire-and-forget" requests where the result must be returned immediately.
### Queue Mode
```shell Shell theme={null}
python app.py --queue
```
* Continuously pulls jobs from Together's managed queue
* Automatic job status reporting
* Graceful shutdown support
* Integrated with autoscaling
### HTTP Mode (Development/Testing)
```shell Shell theme={null}
python app.py
```
* Direct HTTP requests to `/generate`
* Useful for local testing
* Single concurrent request
## Progress Reporting
For long-running jobs like video generation, you can report progress updates that clients can poll for. Call `emit_info()` from inside `predict()` with a dict of progress data:
```python Python theme={null}
from sprocket import Sprocket, emit_info
class VideoGenerator(Sprocket):
def predict(self, args):
for i in range(100):
frame = generate_frame(i)
emit_info({"progress": (i + 1) / 100, "status": "generating"})
return {"video": FileOutput("output.mp4")}
```
Progress updates are batched and merged — frequent calls to `emit_info()` don't create excessive API traffic, and later values overwrite earlier ones for the same keys. The info dict must serialize to less than 4096 bytes of JSON. The runner also sends periodic heartbeats to maintain the job claim even if you don't call `emit_info()`.
Clients poll the [job status endpoint](/reference/queue-status) and see emitted data in the `info` field:
```json theme={null}
{
"request_id": "req_abc123",
"status": "running",
"info": {"progress": 0.75, "status": "generating"}
}
```
***
For the full API reference — class signatures, parameters, environment variables, and complete examples — see the [Sprocket SDK Reference](/reference/dci-reference-sprocket).
## File Handling
Sprocket automatically handles file transfers in both directions.
**Input files:** Any HTTPS URL in the job payload is downloaded to a local `inputs/` directory before `predict()` is called. The URL in the payload is replaced with the local file path, so your code just opens a local file. This works with Together's files API or any public URL.
**Output files:** Return a `FileOutput("path")` in your output dict and Sprocket uploads it to Together storage after `predict()` returns. The `FileOutput` is replaced with the public URL in the final job result.
**The full pipeline for each job is:**
1. Download input URLs → local files
2. Call `predict(args)` with local paths
3. Call `finalize()` on your `InputOutputProcessor` (if you've overridden it)
4. Upload any `FileOutput` values to Together storage
5. Report job result
**Custom I/O:** If you need to process downloaded files before they reach `predict()` (e.g., decompressing), or upload outputs to your own storage instead of Together's, you can subclass `InputOutputProcessor` and attach it to your Sprocket via the `processor` class attribute. See the [reference](/reference/dci-reference-sprocket#custom-io-processing) for the full API.
When using `use_torchrun=True` for multi-GPU inference, all file I/O (downloading inputs, uploading outputs, `finalize()`) runs in the parent process, not in the GPU worker processes. This keeps networking separate from GPU compute.
## Multi-GPU / Distributed Inference
For models that need multiple GPUs (tensor parallelism, context parallelism), pass `use_torchrun=True` to `sprocket.run()` and set `gpu_count` in your Jig config.
The architecture is:
* A **parent process** manages the HTTP server, queue polling, and file I/O
* `torchrun` launches **N child processes** (one per GPU), connected to the parent via a Unix socket
* For each job, the parent broadcasts inputs to all children, each child runs `predict()`, and the parent collects the output from whichever rank returns a non-None value (by convention, rank 0)
Your Sprocket code looks the same as single-GPU, with two additions: initialize `torch.distributed` in `setup()`, and return `None` from non-rank-0 processes:
```python Python theme={null}
import torch
import torch.distributed as dist
import sprocket
class DistributedModel(sprocket.Sprocket):
def setup(self):
dist.init_process_group()
torch.cuda.set_device(dist.get_rank())
self.model = load_and_parallelize_model()
def predict(self, args):
result = self.model.generate(args["prompt"])
if dist.get_rank() == 0:
result.save("output.mp4")
return {"url": sprocket.FileOutput("output.mp4")}
return None
if __name__ == "__main__":
sprocket.run(DistributedModel(), "my-org/my-model", use_torchrun=True)
```
```toml pyproject.toml theme={null}
[tool.jig.deploy]
gpu_type = "h100-80gb"
gpu_count = 4
```
## Error Handling
Sprocket distinguishes between **per-job errors** and **fatal errors**.
**Per-job errors:** If `predict()` raises an exception, the job is marked as `failed` with the error message, downloaded input files are cleaned up, and the worker moves on to the next job. The worker stays healthy — one bad input doesn't take down the whole deployment.
**Fatal errors** trigger a full worker restart (SIGTERM). These occur when:
* A prediction times out (torchrun mode only — exceeds `TERMINATION_GRACE_PERIOD_SECONDS`)
* A torchrun child process crashes or disconnects
* The connection to Together's API is lost
In torchrun mode, the job claim has a 90-second timeout that's refreshed every 45 seconds. If a worker dies mid-job, the queue reclaims the job and assigns it to another worker. In single-GPU mode, claims are held until completion with no timeout.
## Graceful Shutdown
When a container receives SIGTERM (during scale-down or redeployment):
1. Sprocket stops accepting new jobs
2. The current job runs to completion
3. Your `shutdown()` method is called for cleanup
4. The container exits
The total time allowed is controlled by `TERMINATION_GRACE_PERIOD_SECONDS` (default: 300s, configurable in `pyproject.toml`). Set this higher if your jobs are long-running — for example, video generation that takes several minutes per job.
## Running Modes
Sprocket supports two modes: **Queue mode** and **Request mode**.
* **Queue mode** is for workloads that need job durability and tracking — model generations, video rendering, or anything that takes more than a few hundred milliseconds. Jobs are persisted in the queue, survive worker restarts, and support priority ordering and progress reporting.
* **Request mode** (direct HTTP) is for low-latency workloads that don't need queueing — embedding inference, streaming voice models, or other "fire-and-forget" requests where the result must be returned immediately.
### Queue Mode
```shell Shell theme={null}
python app.py --queue
```
* Continuously pulls jobs from Together's managed queue
* Automatic job status reporting
* Graceful shutdown support
* Integrated with autoscaling
### HTTP Mode (Development/Testing)
```shell Shell theme={null}
python app.py
```
* Direct HTTP requests to `/generate`
* Useful for local testing
* Single concurrent request
## Progress Reporting
For long-running jobs like video generation, you can report progress updates that clients can poll for. Call `emit_info()` from inside `predict()` with a dict of progress data:
```python Python theme={null}
from sprocket import Sprocket, emit_info
class VideoGenerator(Sprocket):
def predict(self, args):
for i in range(100):
frame = generate_frame(i)
emit_info({"progress": (i + 1) / 100, "status": "generating"})
return {"video": FileOutput("output.mp4")}
```
Progress updates are batched and merged — frequent calls to `emit_info()` don't create excessive API traffic, and later values overwrite earlier ones for the same keys. The info dict must serialize to less than 4096 bytes of JSON. The runner also sends periodic heartbeats to maintain the job claim even if you don't call `emit_info()`.
Clients poll the [job status endpoint](/reference/queue-status) and see emitted data in the `info` field:
```json theme={null}
{
"request_id": "req_abc123",
"status": "running",
"info": {"progress": 0.75, "status": "generating"}
}
```
***
For the full API reference — class signatures, parameters, environment variables, and complete examples — see the [Sprocket SDK Reference](/reference/dci-reference-sprocket).