> ## Documentation Index
> Fetch the complete documentation index at: https://docs.together.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Sequential workflow
> Coordinating a chain of LLM calls to solve a complex task.
A workflow where the output of one LLM call becomes the input for the next. This sequential design allows for structured reasoning and step-by-step task completion.
## Workflow Architecture
Chain multiple LLM calls sequentially to process complex tasks.
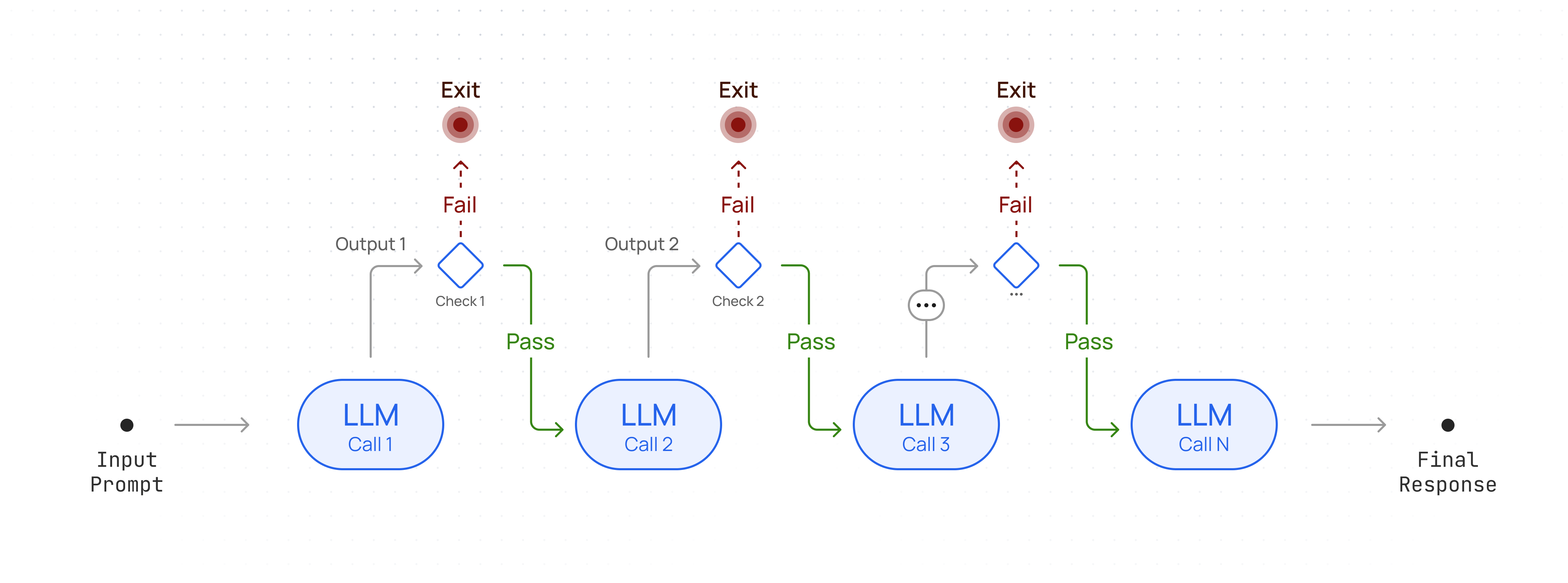 ### Sequential Workflow Cookbook
For a more detailed walk-through refer to the [notebook here](https://github.com/togethercomputer/together-cookbook/blob/main/Agents/Serial_Chain_Agent_Workflow.ipynb)
## Setup Client
```python Python theme={null}
from together import Together
client = Together()
def run_llm(user_prompt: str, model: str, system_prompt: str = None):
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": user_prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.7,
max_tokens=4000,
)
return response.choices[0].message.content
```
```typescript TypeScript theme={null}
import assert from "node:assert";
import Together from "together-ai";
const client = new Together();
export async function runLLM(
userPrompt: string,
model: string,
systemPrompt?: string,
) {
const messages: { role: "system" | "user"; content: string }[] = [];
if (systemPrompt) {
messages.push({ role: "system", content: systemPrompt });
}
messages.push({ role: "user", content: userPrompt });
const response = await client.chat.completions.create({
model,
messages,
temperature: 0.7,
max_tokens: 4000,
});
const content = response.choices[0].message?.content;
assert(typeof content === "string");
return content;
}
```
## Implement Workflow
```python Python theme={null}
from typing import List
def serial_chain_workflow(
input_query: str,
prompt_chain: List[str],
) -> List[str]:
"""Run a serial chain of LLM calls to address the `input_query`
using a list of prompts specified in `prompt_chain`.
"""
response_chain = []
response = input_query
for i, prompt in enumerate(prompt_chain):
print(f"Step {i+1}")
response = run_llm(
f"{prompt}\nInput:\n{response}",
model="meta-llama/Llama-3.3-70B-Instruct-Turbo",
)
response_chain.append(response)
print(f"{response}\n")
return response_chain
```
```typescript TypeScript theme={null}
/*
Run a serial chain of LLM calls to address the `inputQuery`
using a list of prompts specified in `promptChain`.
*/
async function serialChainWorkflow(inputQuery: string, promptChain: string[]) {
const responseChain: string[] = [];
let response = inputQuery;
for (const prompt of promptChain) {
console.log(`Step ${promptChain.indexOf(prompt) + 1}`);
response = await runLLM(
`${prompt}\nInput:\n${response}`,
"meta-llama/Llama-3.3-70B-Instruct-Turbo",
);
console.log(`${response}\n`);
responseChain.push(response);
}
return responseChain;
}
```
## Example Usage
```python Python theme={null}
question = "Sally earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?"
prompt_chain = [
"""Given the math problem, ONLY extract any relevant numerical information and how it can be used.""",
"""Given the numerical information extracted, ONLY express the steps you would take to solve the problem.""",
"""Given the steps, express the final answer to the problem.""",
]
responses = serial_chain_workflow(question, prompt_chain)
final_answer = responses[-1]
```
```typescript TypeScript theme={null}
const question =
"Sally earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?";
const promptChain = [
"Given the math problem, ONLY extract any relevant numerical information and how it can be used.",
"Given the numerical information extracted, ONLY express the steps you would take to solve the problem.",
"Given the steps, express the final answer to the problem.",
];
async function main() {
await serialChainWorkflow(question, promptChain);
}
main();
```
## Use cases
* Generating Marketing copy, then translating it into a different language.
* Writing an outline of a document, checking that the outline meets certain criteria, then writing the document based on the outline.
* Using an LLM to clean and standardize raw data, then passing the cleaned data to another LLM for insights, summaries, or visualizations.
* Generating a set of detailed questions based on a topic with one LLM, then passing those questions to another LLM to produce well-researched answers.
### Sequential Workflow Cookbook
For a more detailed walk-through refer to the [notebook here](https://github.com/togethercomputer/together-cookbook/blob/main/Agents/Serial_Chain_Agent_Workflow.ipynb)
## Setup Client
```python Python theme={null}
from together import Together
client = Together()
def run_llm(user_prompt: str, model: str, system_prompt: str = None):
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": user_prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.7,
max_tokens=4000,
)
return response.choices[0].message.content
```
```typescript TypeScript theme={null}
import assert from "node:assert";
import Together from "together-ai";
const client = new Together();
export async function runLLM(
userPrompt: string,
model: string,
systemPrompt?: string,
) {
const messages: { role: "system" | "user"; content: string }[] = [];
if (systemPrompt) {
messages.push({ role: "system", content: systemPrompt });
}
messages.push({ role: "user", content: userPrompt });
const response = await client.chat.completions.create({
model,
messages,
temperature: 0.7,
max_tokens: 4000,
});
const content = response.choices[0].message?.content;
assert(typeof content === "string");
return content;
}
```
## Implement Workflow
```python Python theme={null}
from typing import List
def serial_chain_workflow(
input_query: str,
prompt_chain: List[str],
) -> List[str]:
"""Run a serial chain of LLM calls to address the `input_query`
using a list of prompts specified in `prompt_chain`.
"""
response_chain = []
response = input_query
for i, prompt in enumerate(prompt_chain):
print(f"Step {i+1}")
response = run_llm(
f"{prompt}\nInput:\n{response}",
model="meta-llama/Llama-3.3-70B-Instruct-Turbo",
)
response_chain.append(response)
print(f"{response}\n")
return response_chain
```
```typescript TypeScript theme={null}
/*
Run a serial chain of LLM calls to address the `inputQuery`
using a list of prompts specified in `promptChain`.
*/
async function serialChainWorkflow(inputQuery: string, promptChain: string[]) {
const responseChain: string[] = [];
let response = inputQuery;
for (const prompt of promptChain) {
console.log(`Step ${promptChain.indexOf(prompt) + 1}`);
response = await runLLM(
`${prompt}\nInput:\n${response}`,
"meta-llama/Llama-3.3-70B-Instruct-Turbo",
);
console.log(`${response}\n`);
responseChain.push(response);
}
return responseChain;
}
```
## Example Usage
```python Python theme={null}
question = "Sally earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?"
prompt_chain = [
"""Given the math problem, ONLY extract any relevant numerical information and how it can be used.""",
"""Given the numerical information extracted, ONLY express the steps you would take to solve the problem.""",
"""Given the steps, express the final answer to the problem.""",
]
responses = serial_chain_workflow(question, prompt_chain)
final_answer = responses[-1]
```
```typescript TypeScript theme={null}
const question =
"Sally earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?";
const promptChain = [
"Given the math problem, ONLY extract any relevant numerical information and how it can be used.",
"Given the numerical information extracted, ONLY express the steps you would take to solve the problem.",
"Given the steps, express the final answer to the problem.",
];
async function main() {
await serialChainWorkflow(question, promptChain);
}
main();
```
## Use cases
* Generating Marketing copy, then translating it into a different language.
* Writing an outline of a document, checking that the outline meets certain criteria, then writing the document based on the outline.
* Using an LLM to clean and standardize raw data, then passing the cleaned data to another LLM for insights, summaries, or visualizations.
* Generating a set of detailed questions based on a topic with one LLM, then passing those questions to another LLM to produce well-researched answers.