Download and View the Dataset
Shell
Python
Implement Semantic Search Pipeline
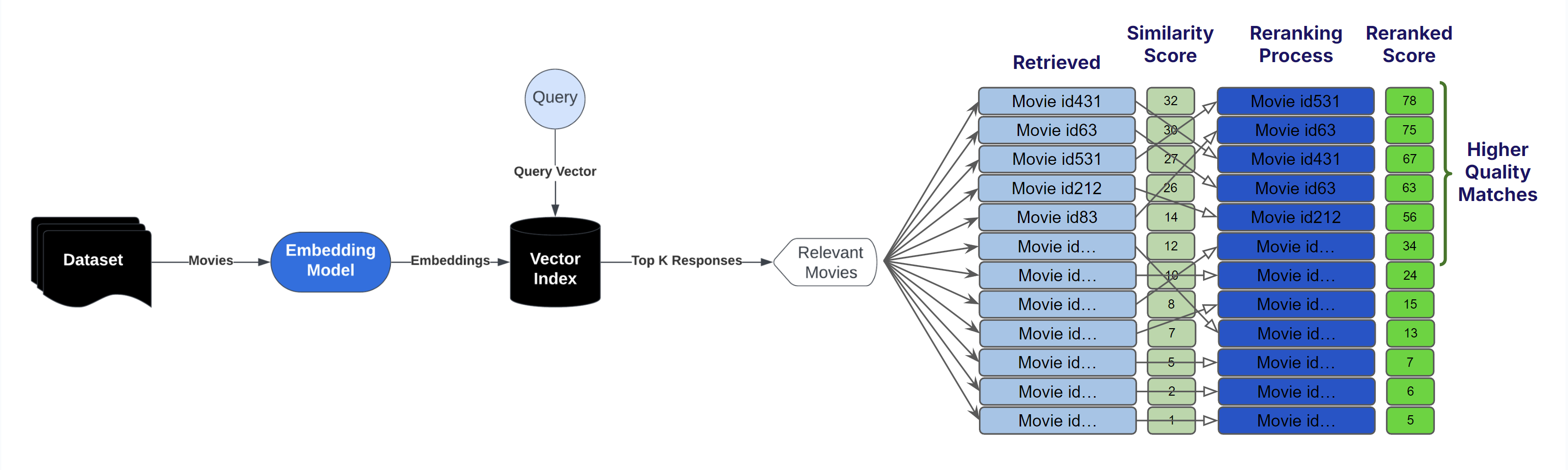
Below we implement a simple semantic search pipeline:- Embed movie documents + query
- Obtain a list of movies ranked based on cosine similarities between the query and movie vectors.
Python
Python
Python
Python
Use Llama Rank to Rerank Top 25 Movies
Treating the top 25 matching movies as good candidate matches, potentially with irrelevant false positives, that might have snuck in we want to have the reranker model look and rerank each based on similarity to the query.Python
multilingual-e5-large-instruct embedding model gives us a fuzzy match to concepts mentioned in the query, the Llama-Rank-V1 reranker then improves the quality of our list further by spending more compute to resort the list of movies.
Learn more about how to use reranker models in the docs here!