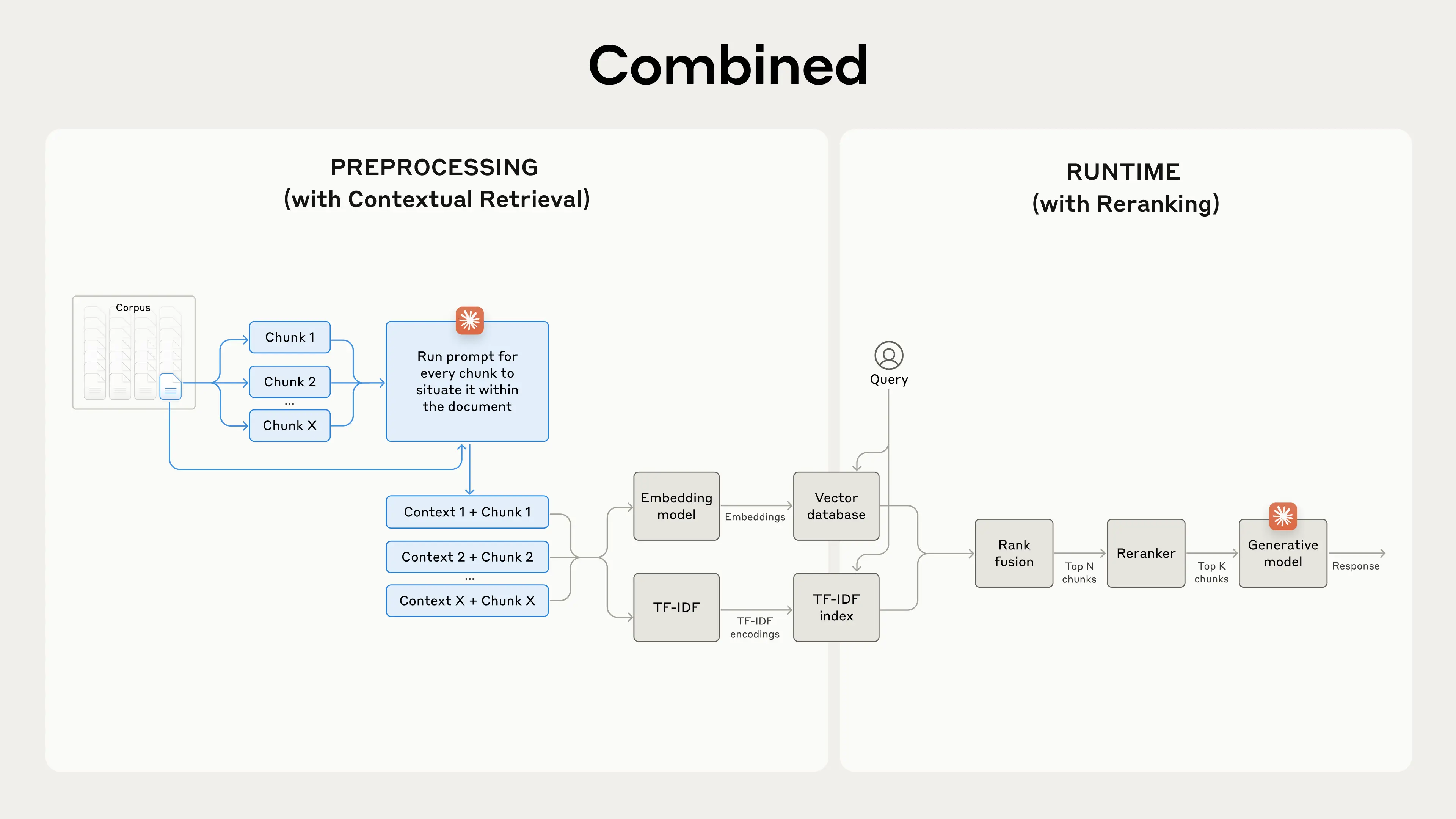
Contextual RAG:
- For every chunk - prepend an explanatory context snippet that situates the chunk within the rest of the document. -> Get a small cost effective LLM to do this.
- Hybrid Search: Embed the chunk using both sparse (keyword) and dense(semantic) embeddings.
- Perform rank fusion using an algorithm like Reciprocal Rank Fusion(RRF).
- Retrieve top 150 chunks and pass those to a Reranker to obtain top 20 chunks.
- Pass top 20 chunks to LLM to generate an answer.
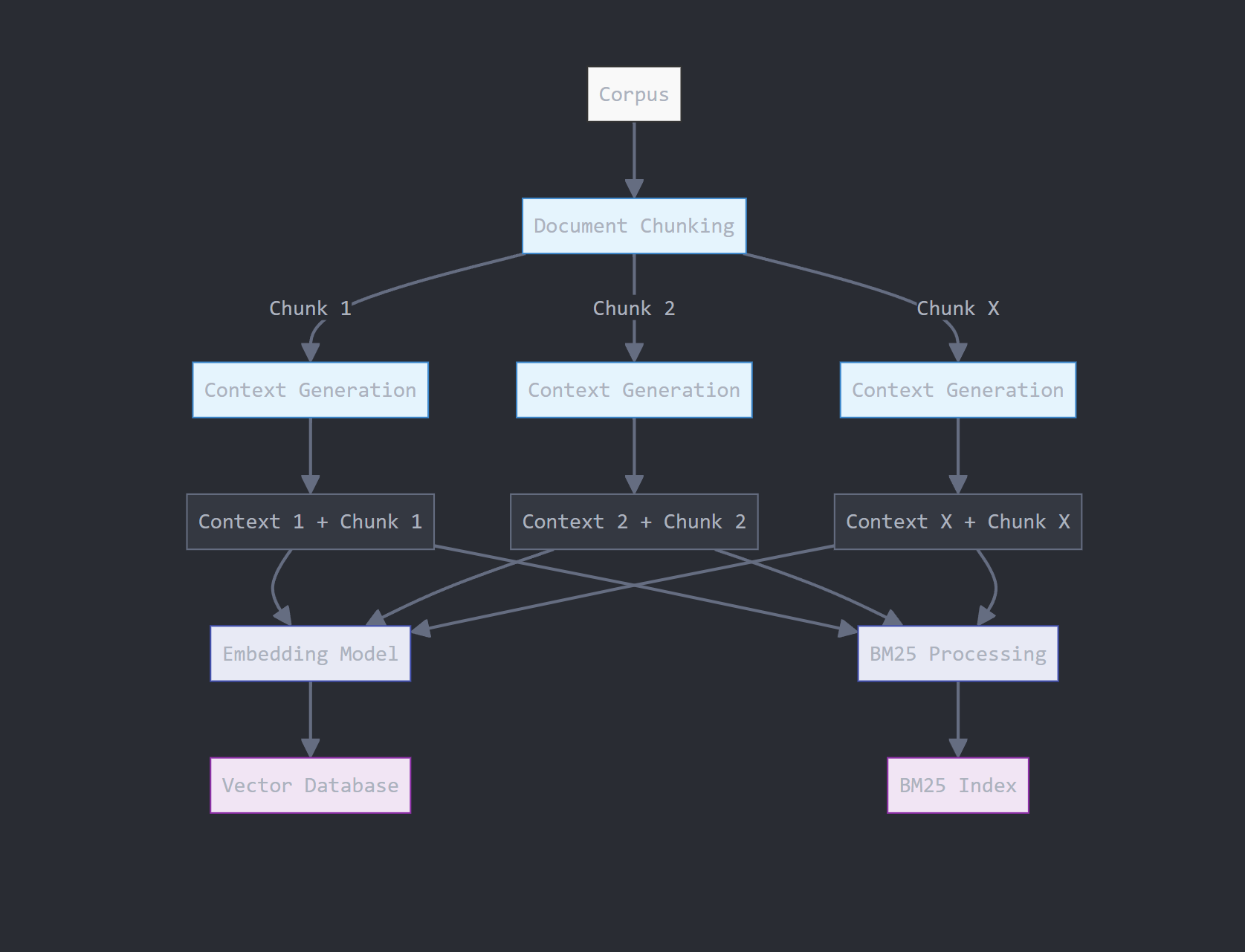
- Data processing and chunking
- Context generation using Qwen3.5-9B
- Vector Embedding and Index Generation
- BM25 Keyword Index Generation
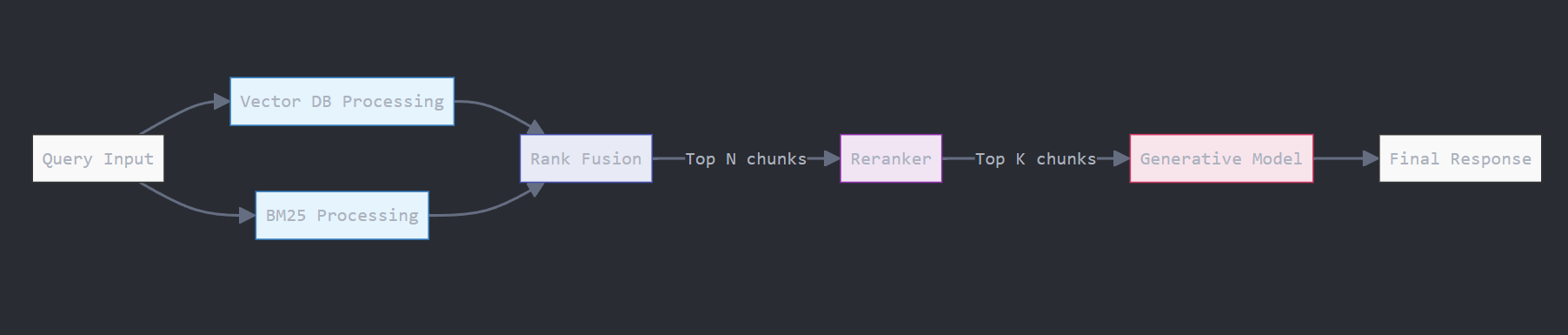
- Perform retrieval using both indices and combine them using RRF
- Reranker to improve retrieval quality
- Generation with Llama3.1 405B
Install Libraries
Data Processing and Chunking

Python
Python
Generating Contextual Chunks
This part contains the main intuition behindContextual Retrieval. We will make an LLM call for each chunk to add much needed relevant context to the chunk. In order to do this we pass in the ENTIRE document per LLM call.
It may seem that passing in the entire document per chunk and making an LLM call per chunk is quite inefficient, this is true and there very well might be more efficient techniques to accomplish the same end goal. But in keeping with implementing the current technique at hand let’s do it.
Additionally using quantized small 1-3B models (here we will use Llama 3.2 3B) along with prompt caching does make this more feasible.
Prompt caching allows key and value matrices corresponding to the document to be cached for future LLM calls.
We will use the following prompt to generate context for each chunk:
Python
Python
Python
Vector Index
We will now usemultilingual-e5-large-instruct to embed the augmented chunks above into a vector index.
Python
Python
BM25 Index
Let’s build a keyword index that allows us to use BM25 to perform lexical search based on the words present in the query and the contextual chunks. For this we will use thebm25s python library:
Python
Python
Python
Everything below this point will happen at query time!
Once a user submits a query we are going to use both functions above to perform Vector and BM25 retrieval and then fuse the ranks using the RRF algorithm implemented below.Python
Python
Python
Reranker To improve Quality
Now we add a retrieval quality improvement step here to make sure only the highest and most semantically similar chunks get sent to our LLM.Python
Call Generative Model - Llama 3.1 405B
We will pass the finalized 3 chunks into an LLM to get our final answer.Python