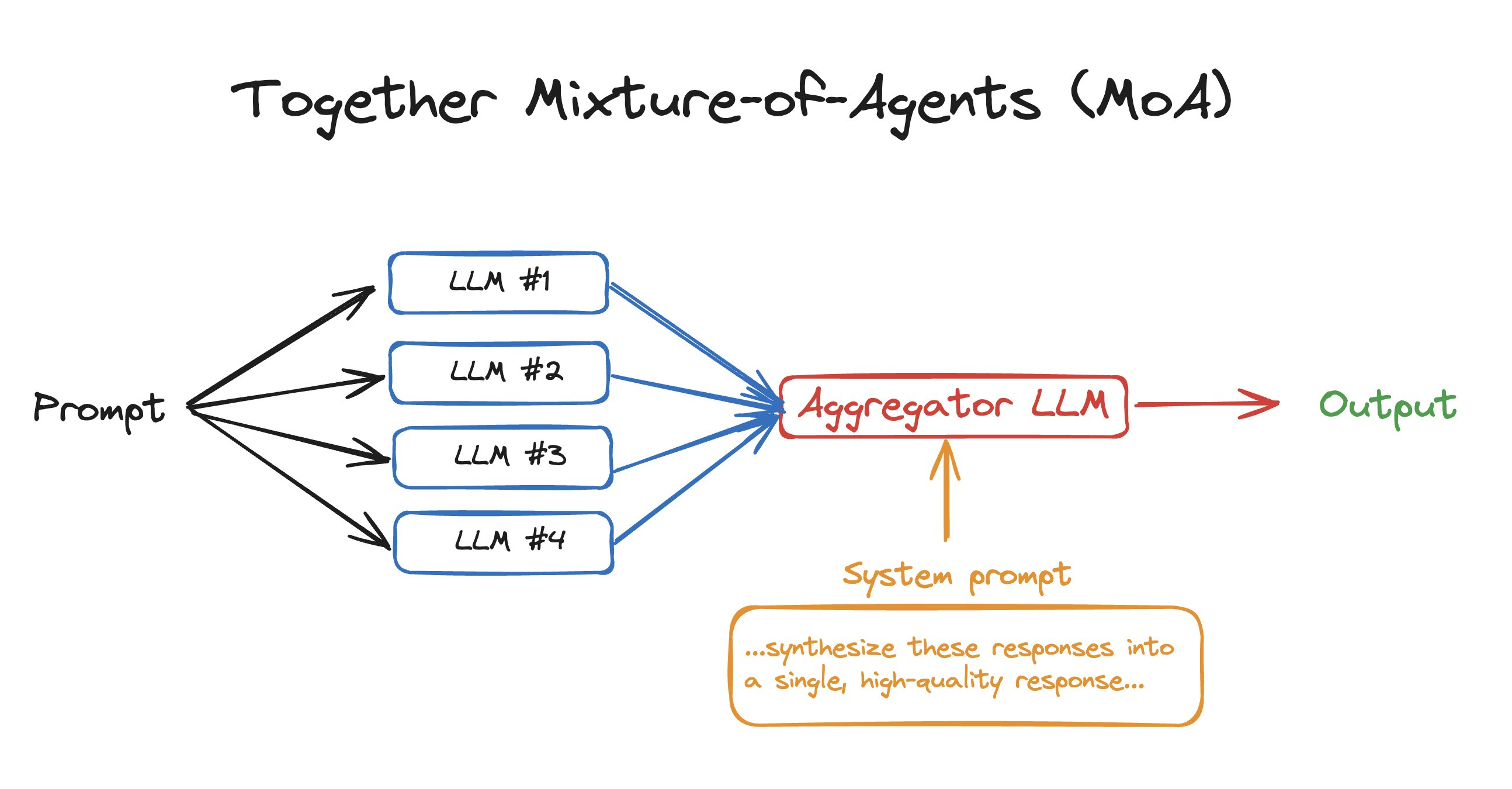
What is Together MoA?
Mixture of Agents (MoA) is a novel approach that leverages the collective strengths of multiple LLMs to enhance performance, achieving state-of-the-art results. By employing a layered architecture where each layer comprises several LLM agents, MoA significantly outperforms GPT-4 Omni’s 57.5% on AlpacaEval 2.0 with a score of 65.1%, using only open-source models! The way Together MoA works is that given a prompt, liketell me the best things to do in SF, it sends it to 4 different OSS LLMs. It then combines results from all 4, sends it to a final LLM, and asks it to combine all 4 responses into an ideal response. That’s it! It’s just the idea of combining the results of 4 different LLMs to produce a better final output. It’s slower than using a single LLM, but it can be great for use cases where latency doesn’t matter as much, like synthetic data generation.
For a quick summary and 3-minute demo on how to implement MoA with code, watch the video below:
Together MoA in 50 lines of code
To get started with using MoA in your own apps, you’ll need to install the Together python library, get your Together API key, and run the code below which uses our chat completions API to interact with OSS models.- Install the Together Python library
Shell
- Get your Together API key & export it
Shell
- Run the code below, which interacts with our chat completions API.
Python
Advanced MoA example
In the previous example, we went over how to implement MoA with 2 layers (4 LLMs answering and one LLM aggregating). However, one strength of MoA is being able to go through several layers to get an even better response. In this example, we’ll go through how to run MoA with 3+ layers.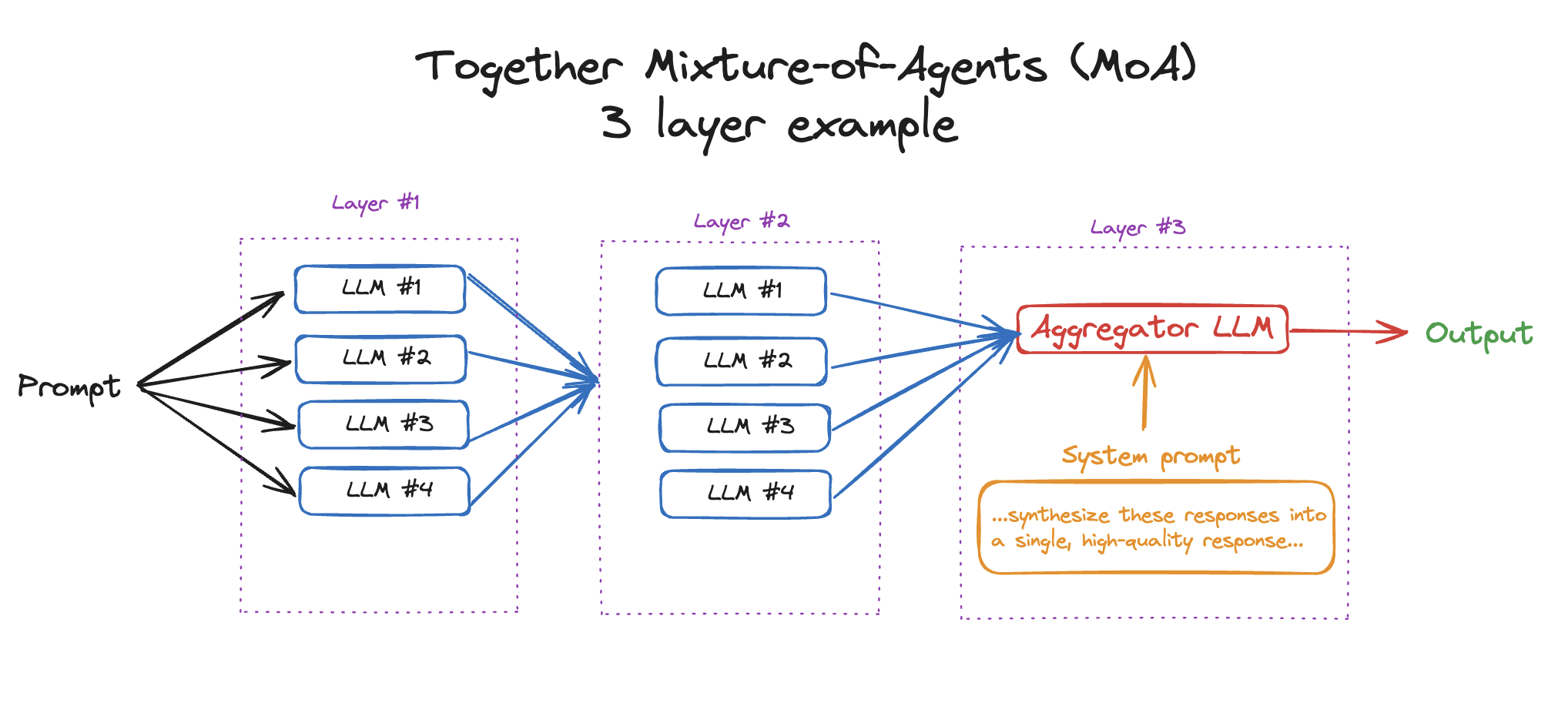
Python
Resources
- Together MoA GitHub Repo (includes an interactive demo)
- Together MoA blog post
- MoA Technical Paper