Introduction
For AI models to be effective in specialized tasks, they often require domain-specific knowledge. For instance, a financial advisory chatbot needs to understand market trends and products offered by a specific bank, while an AI legal assistant must be equipped with knowledge of statutes, regulations, and past case law. A common solution is Retrieval-Augmented Generation (RAG), which retrieves relevant data from a knowledge base and combines it with the user’s prompt, thereby improving and customizing the model’s output to the provided data.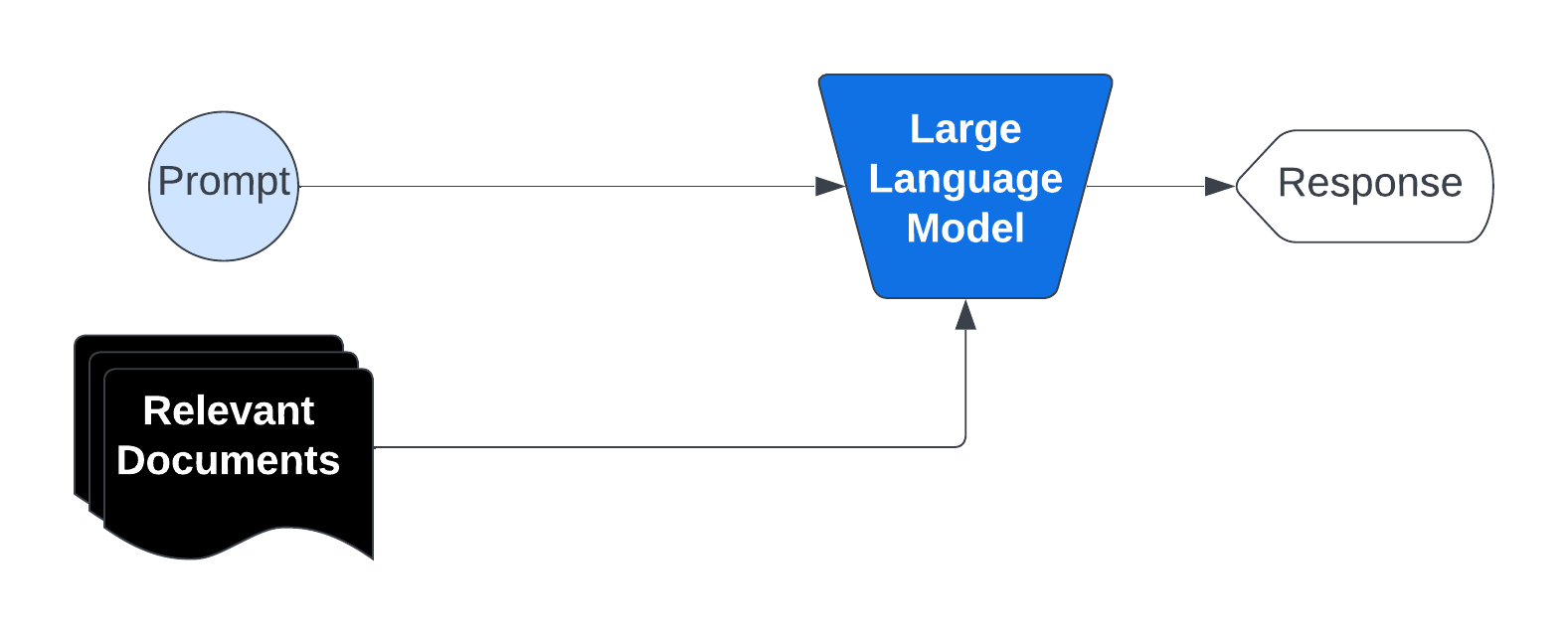
RAG Explanation
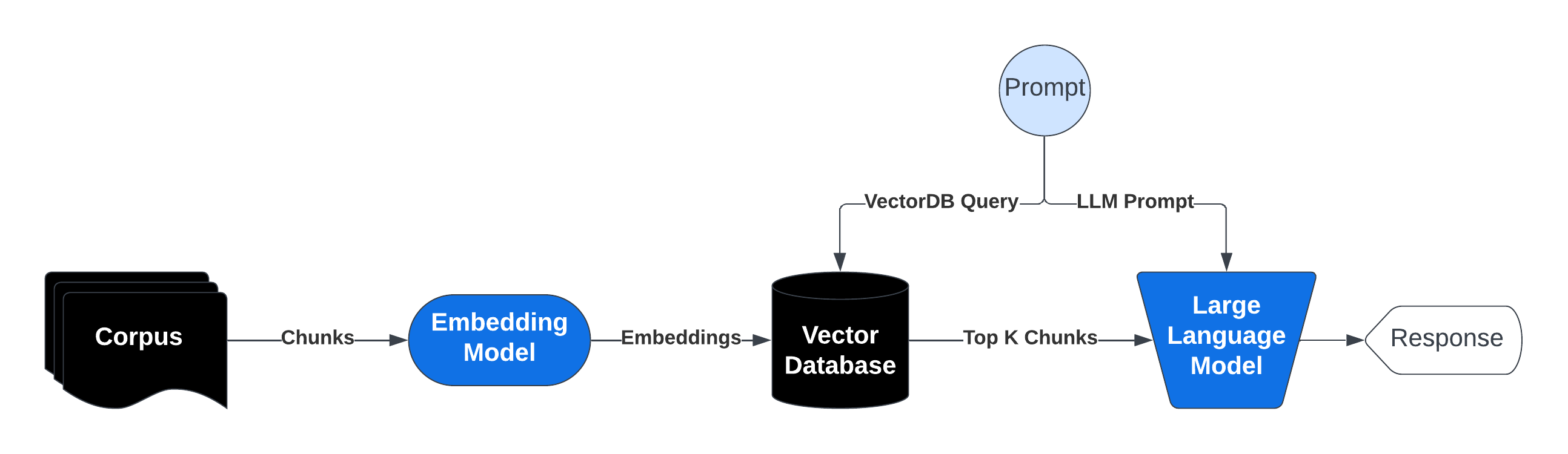
RAG operates by preprocessing a large knowledge base and dynamically retrieving relevant information at runtime. Here’s a breakdown of the process:- Indexing the Knowledge Base: The corpus (collection of documents) is divided into smaller, manageable chunks of text. Each chunk is converted into a vector embedding using an embedding model. These embeddings are stored in a vector database optimized for similarity searches.
- Query Processing and Retrieval: When a user submits a prompt that would initially go directly to an LLM we process that and extract a query, the system searches the vector database for chunks semantically similar to the query. The most relevant chunks are retrieved and injected into the prompt sent to the generative AI model.
- Response Generation: The AI model then uses the retrieved information along with its pre-trained knowledge to generate a response. Not only does this reduce the likelihood of hallucination since relevant context is provided directly in the prompt but it also allows us to cite to source material as well.
Download and View the Dataset
Shell
Python
Python
Implement Retrieval Pipeline - “R” part of RAG
Below we implement a simple retrieval pipeline:- Embed movie documents and query
- Obtain top k movies ranked based on cosine similarities between the query and movie vectors.
Python
Python
super hero action movie with a timeline twist
Python
We can encapsulate the above in a function
Python
Python
Generation Step - “G” part of RAG
Below we will inject/augment the information the retrieval pipeline extracts into the prompt to the Llama3 8b Model. This will help guide the generation by grounding it from facts in our knowledge base!Python
Text