Workflow Architecture
Build an agent that iteratively improves responses.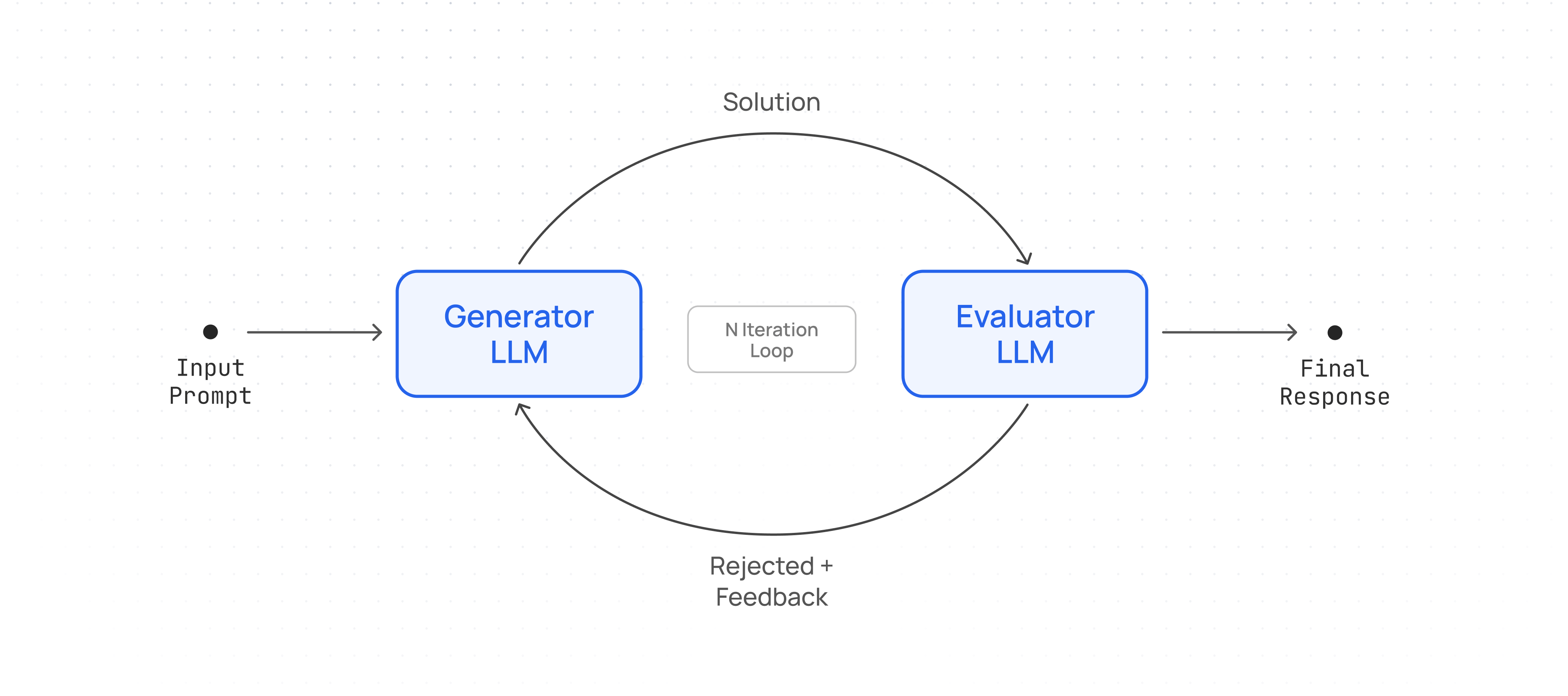
Setup Client & Helper Functions
import json
from pydantic import ValidationError
from together import Together
client = Together()
def run_llm(user_prompt: str, model: str, system_prompt: str = None):
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": user_prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.7,
max_tokens=4000,
)
return response.choices[0].message.content
def JSON_llm(user_prompt: str, schema, system_prompt: str = None):
try:
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": user_prompt})
extract = client.chat.completions.create(
messages=messages,
model="meta-llama/Llama-3.3-70B-Instruct-Turbo",
response_format={
"type": "json_schema",
"json_schema": {
"name": "response",
"schema": schema.model_json_schema(),
},
},
)
return json.loads(extract.choices[0].message.content)
except ValidationError as e:
error_message = f"Failed to parse JSON: {e}"
print(error_message)
import assert from "node:assert";
import Together from "together-ai";
import { z, type ZodType } from "zod";
const client = new Together();
export async function runLLM(userPrompt: string, model: string) {
const response = await client.chat.completions.create({
model,
messages: [{ role: "user", content: userPrompt }],
temperature: 0.7,
max_tokens: 4000,
});
const content = response.choices[0].message?.content;
assert(typeof content === "string");
return content;
}
export async function jsonLLM<T>(
userPrompt: string,
schema: ZodType<T>,
systemPrompt?: string,
) {
const messages: { role: "system" | "user"; content: string }[] = [];
if (systemPrompt) {
messages.push({ role: "system", content: systemPrompt });
}
messages.push({ role: "user", content: userPrompt });
const response = await client.chat.completions.create({
model: "meta-llama/Llama-3.3-70B-Instruct-Turbo",
messages,
response_format: {
type: "json_schema",
json_schema: {
name: "response",
schema: z.toJSONSchema(schema),
},
},
});
const content = response.choices[0].message?.content;
assert(typeof content === "string");
return schema.parse(JSON.parse(content));
}
Implement Workflow
from pydantic import BaseModel
from typing import Literal
GENERATOR_PROMPT = """
Your goal is to complete the task based on <user input>. If there are feedback
from your previous generations, you should reflect on them to improve your solution
Output your answer concisely in the following format:
Thoughts:
[Your understanding of the task and feedback and how you plan to improve]
Response:
[Your code implementation here]
"""
def generate(
task: str,
generator_prompt: str,
context: str = "",
) -> tuple[str, str]:
"""Generate and improve a solution based on feedback."""
full_prompt = (
f"{generator_prompt}\n{context}\nTask: {task}"
if context
else f"{generator_prompt}\nTask: {task}"
)
response = run_llm(
full_prompt, model="Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8"
)
print("\n## Generation start")
print(f"Output:\n{response}\n")
return response
EVALUATOR_PROMPT = """
Evaluate this following code implementation for:
1. code correctness
2. time complexity
3. style and best practices
You should be evaluating only and not attempting to solve the task.
Only output "PASS" if all criteria are met and you have no further suggestions for improvements.
Provide detailed feedback if there are areas that need improvement. You should specify what needs improvement and why.
Only output JSON.
"""
def evaluate(
task: str,
evaluator_prompt: str,
generated_content: str,
schema,
) -> tuple[str, str]:
"""Evaluate if a solution meets requirements."""
full_prompt = f"{evaluator_prompt}\nOriginal task: {task}\nContent to evaluate: {generated_content}"
# Build a schema for the evaluation
class Evaluation(BaseModel):
evaluation: Literal["PASS", "NEEDS_IMPROVEMENT", "FAIL"]
feedback: str
response = JSON_llm(full_prompt, Evaluation)
evaluation = response["evaluation"]
feedback = response["feedback"]
print("## Evaluation start")
print(f"Status: {evaluation}")
print(f"Feedback: {feedback}")
return evaluation, feedback
def loop_workflow(
task: str, evaluator_prompt: str, generator_prompt: str
) -> tuple[str, list[dict]]:
"""Keep generating and evaluating until the evaluator passes the last generated response."""
# Store previous responses from generator
memory = []
# Generate initial response
response = generate(task, generator_prompt)
memory.append(response)
# While the generated response is not passing, keep generating and evaluating
while True:
evaluation, feedback = evaluate(task, evaluator_prompt, response)
# Terminating condition
if evaluation == "PASS":
return response
# Add current response and feedback to context and generate a new response
context = "\n".join(
[
"Previous attempts:",
*[f"- {m}" for m in memory],
f"\nFeedback: {feedback}",
]
)
response = generate(task, generator_prompt, context)
memory.append(response)
import dedent from "dedent";
import { z } from "zod";
const GENERATOR_PROMPT = dedent`
Your goal is to complete the task based on <user input>. If there is feedback
from your previous generations, you should reflect on them to improve your solution.
Output your answer concisely in the following format:
Thoughts:
[Your understanding of the task and feedback and how you plan to improve]
Response:
[Your code implementation here]
`;
/*
Generate and improve a solution based on feedback.
*/
async function generate(task: string, generatorPrompt: string, context = "") {
const fullPrompt = dedent`
${generatorPrompt}
Task: ${task}
${context}
`;
const response = await runLLM(fullPrompt, "Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8");
console.log(dedent`
## Generation start
${response}
\n
`);
return response;
}
const EVALUATOR_PROMPT = dedent`
Evaluate this following code implementation for:
1. code correctness
2. time complexity
3. style and best practices
You should be evaluating only and not attempting to solve the task.
Only output "PASS" if all criteria are met and you have no further suggestions for improvements.
Provide detailed feedback if there are areas that need improvement. You should specify what needs improvement and why. Make sure to only use a single line without newlines for the feedback.
Only output JSON.
`;
/*
Evaluate if a solution meets the requirements.
*/
async function evaluate(
task: string,
evaluatorPrompt: string,
generatedContent: string,
) {
const fullPrompt = dedent`
${evaluatorPrompt}
Original task: ${task}
Content to evaluate: ${generatedContent}
`;
const schema = z.object({
evaluation: z.enum(["PASS", "NEEDS_IMPROVEMENT", "FAIL"]),
feedback: z.string(),
});
const { evaluation, feedback } = await jsonLLM(fullPrompt, schema);
console.log(dedent`
## Evaluation start
Status: ${evaluation}
Feedback: ${feedback}
\n
`);
return { evaluation, feedback };
}
/*
Keep generating and evaluating until the evaluator passes the last generated response.
*/
async function loopWorkflow(
task: string,
evaluatorPrompt: string,
generatorPrompt: string,
) {
// Store previous responses from generator
const memory = [];
// Generate initial response
let response = await generate(task, generatorPrompt);
memory.push(response);
while (true) {
const { evaluation, feedback } = await evaluate(
task,
evaluatorPrompt,
response,
);
if (evaluation === "PASS") {
break;
}
const context = dedent`
Previous attempts:
${memory.map((m, i) => `### Attempt ${i + 1}\n\n${m}`).join("\n\n")}
Feedback: ${feedback}
`;
response = await generate(task, generatorPrompt, context);
memory.push(response);
}
}
Example Usage
task = """
Implement a Stack with:
1. push(x)
2. pop()
3. getMin()
All operations should be O(1).
"""
loop_workflow(task, EVALUATOR_PROMPT, GENERATOR_PROMPT)
const task = dedent`
Implement a Stack with:
1. push(x)
2. pop()
3. getMin()
All operations should be O(1).
`;
loopWorkflow(task, EVALUATOR_PROMPT, GENERATOR_PROMPT);
Use cases
- Generating code that meets specific requirements, such as ensuring runtime complexity.
- Searching for information and using an evaluator to verify that the results include all the required details.
- Writing a story or article with specific tone or style requirements and using an evaluator to ensure the output matches the desired criteria, such as adhering to a particular voice or narrative structure.
- Generating structured data from unstructured input and using an evaluator to verify that the data is properly formatted, complete, and consistent.
- Creating user interface text, like tooltips or error messages, and using an evaluator to confirm the text is concise, clear, and contextually appropriate.