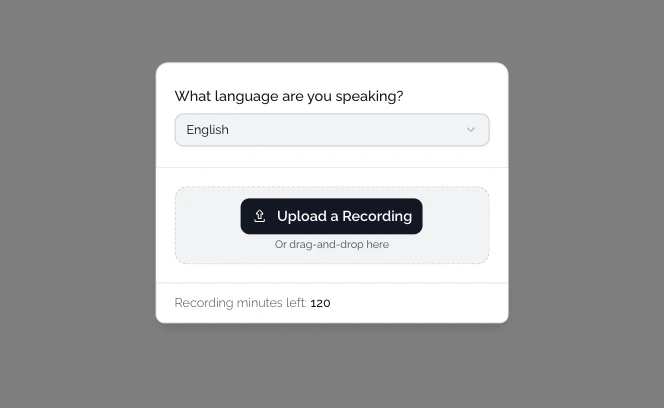
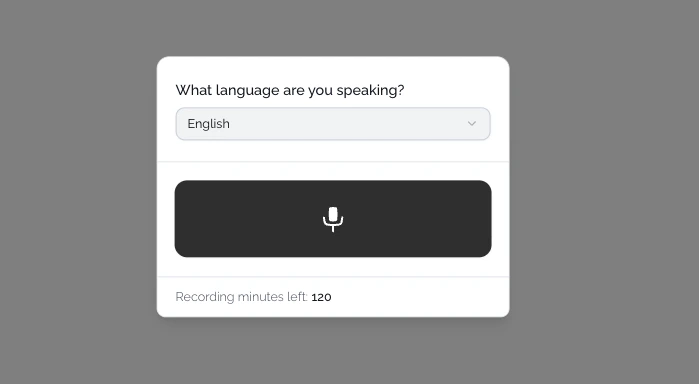
Building the audio recording interface
useAudioRecording hook, which handles all the browser audio recording logic.
Recording audio in the browser
To capture audio, we use the MediaRecorder API with a simple hook:Uploading and transcribing audio
Once we have our audio blob (from recording) or file (from upload), we need to send it to Together AI’s Whisper model. We use S3 for temporary storage and tRPC for type-safe API calls:Creating the transcription API with tRPC
Our backend uses tRPC to provide end-to-end type safety. Here’s our transcription endpoint:Supporting file uploads