Parallel Architecture
Run multiple LLMs in parallel and aggregate their solutions.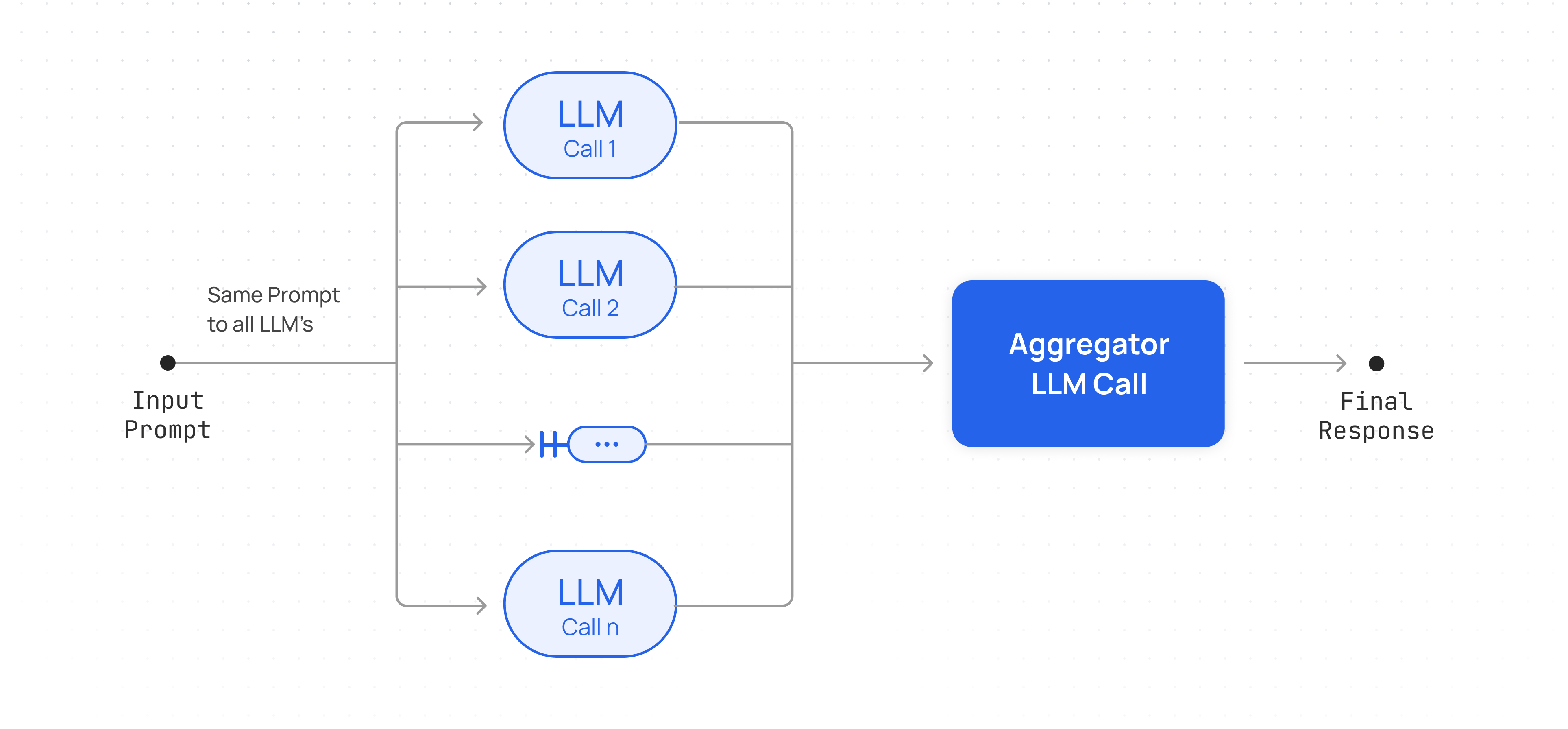
Notice that the same user prompt goes to each parallel LLM for execution. An alternate parallel workflow where this main prompt task is broken into sub-tasks is presented later.
Parallel Workflow Cookbook
For a more detailed walk-through refer to the notebook here.Setup Client & Helper Functions
Implement Workflow
Example Usage
Use cases
- Using one LLM to answer a user’s question, while at the same time using another to screen the question for inappropriate content or requests.
- Reviewing a piece of code for both security vulnerabilities and stylistic improvements at the same time.
- Analyzing a lengthy document by dividing it into sections and assigning each section to a separate LLM for summarization, then combining the summaries into a comprehensive overview.
- Simultaneously analyzing a text for emotional tone, intent, and potential biases, with each aspect handled by a dedicated LLM.
- Translating a document into multiple languages at the same time by assigning each language to a separate LLM, then aggregating the results for multilingual output.
Subtask Agent Workflow
An alternate and useful parallel workflow. This workflow begins with an LLM breaking down the task into subtasks that are dynamically determined based on the input. These subtasks are then processed in parallel by multiple worker LLMs. Finally, the orchestrator LLM synthesizes the workers’ outputs into the final result.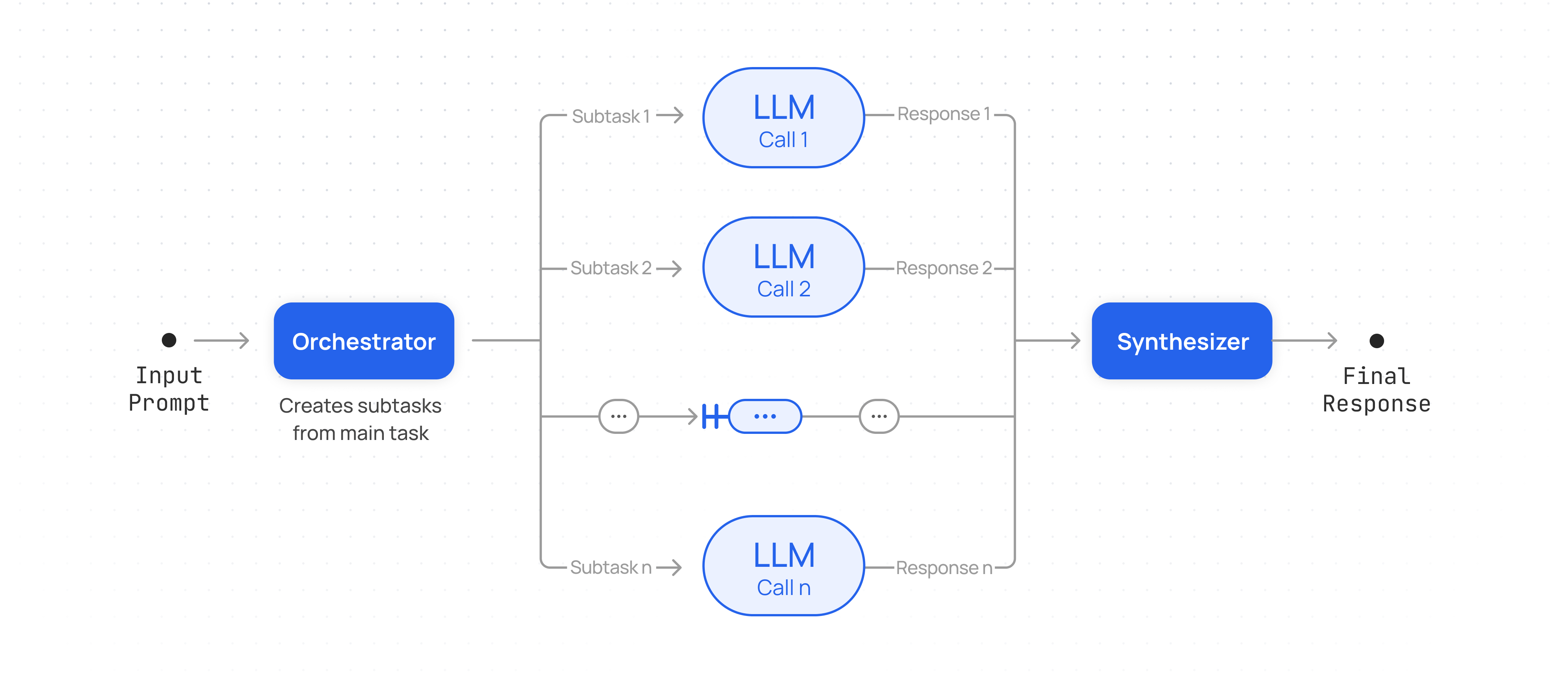
Subtask Workflow Cookbook
For a more detailed walk-through refer to the notebook here.Setup Client & Helper Functions
Implement Workflow
Example Usage
Use cases
- Breaking down a coding problem into subtasks, using an LLM to generate code for each subtask, and making a final LLM call to combine the results into a complete solution.
- Searching for data across multiple sources, using an LLM to identify relevant sources, and synthesizing the findings into a cohesive answer.
- Creating a tutorial by splitting each section into subtasks like writing an introduction, outlining steps, and generating examples. Worker LLMs handle each part, and the orchestrator combines them into a polished final document.
- Dividing a data analysis task into subtasks like cleaning the data, identifying trends, and generating visualizations. Each step is handled by separate worker LLMs, and the orchestrator integrates their findings into a complete analytical report.