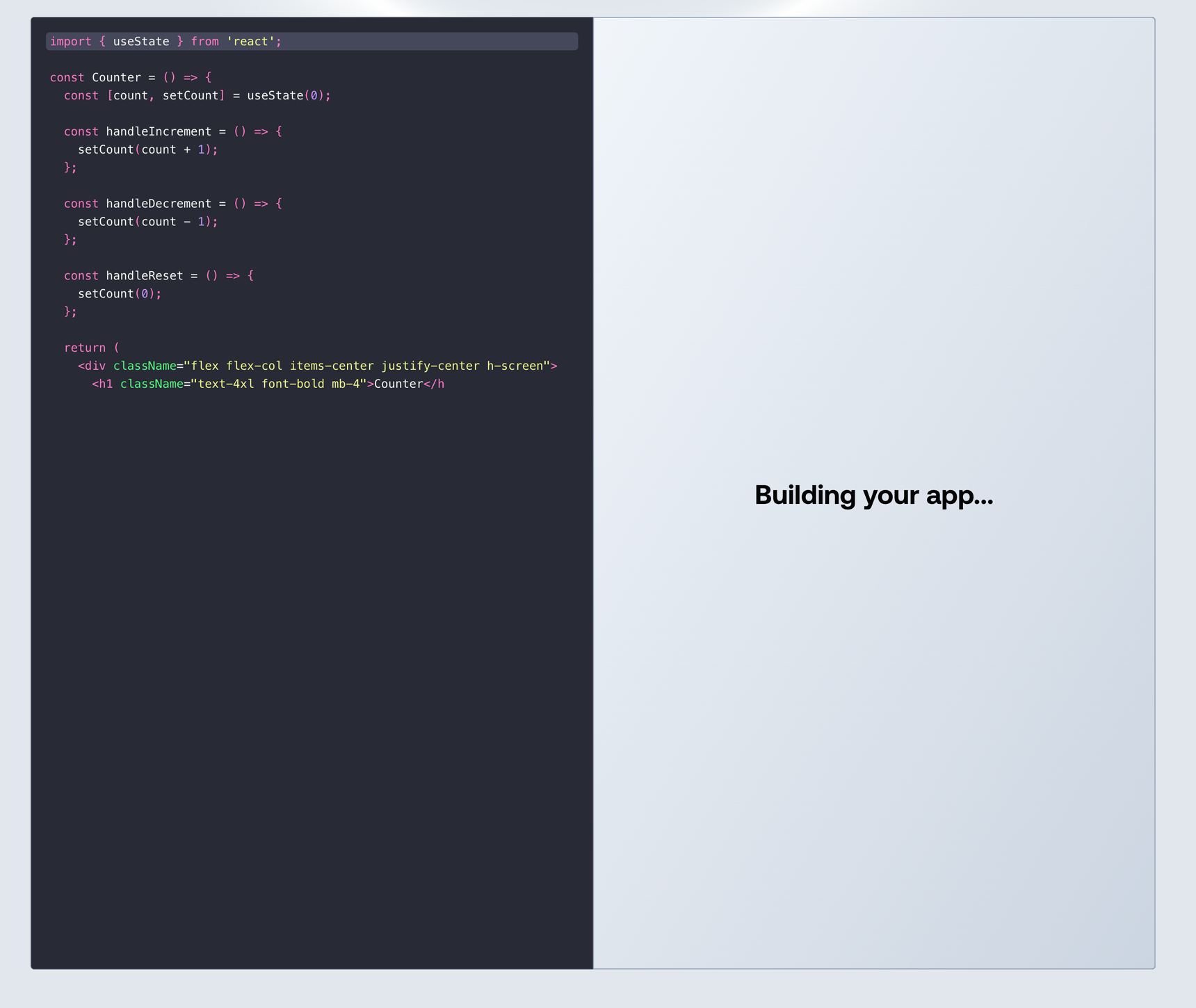
Scaffolding the initial UI
The core interaction of LlamaCoder is a text field where the user can enter a prompt for an app they’d like to build. So to start, we need that text field:
JSX
createApp, since it’s going to take the user’s prompt and generate the corresponding app code:
JSX
/api/generateCode, and we’ll make it a POST endpoint so we can send along the prompt in the request body:
JSX
Generating code in an API route
To create an API route in the Next.js 14 app directory, we can make a newroute.js file:
JSX
Shell
JSX
together.chat.completions.create to get a new response from the LLM. We’ve supplied it with a “system” message telling the LLM that it should behave as if it’s an expert React engineer. Finally, we provide it with the user’s prompt as the second message.
Since we return a JSON object, let’s update our React code to read the JSON from the response:
JSX

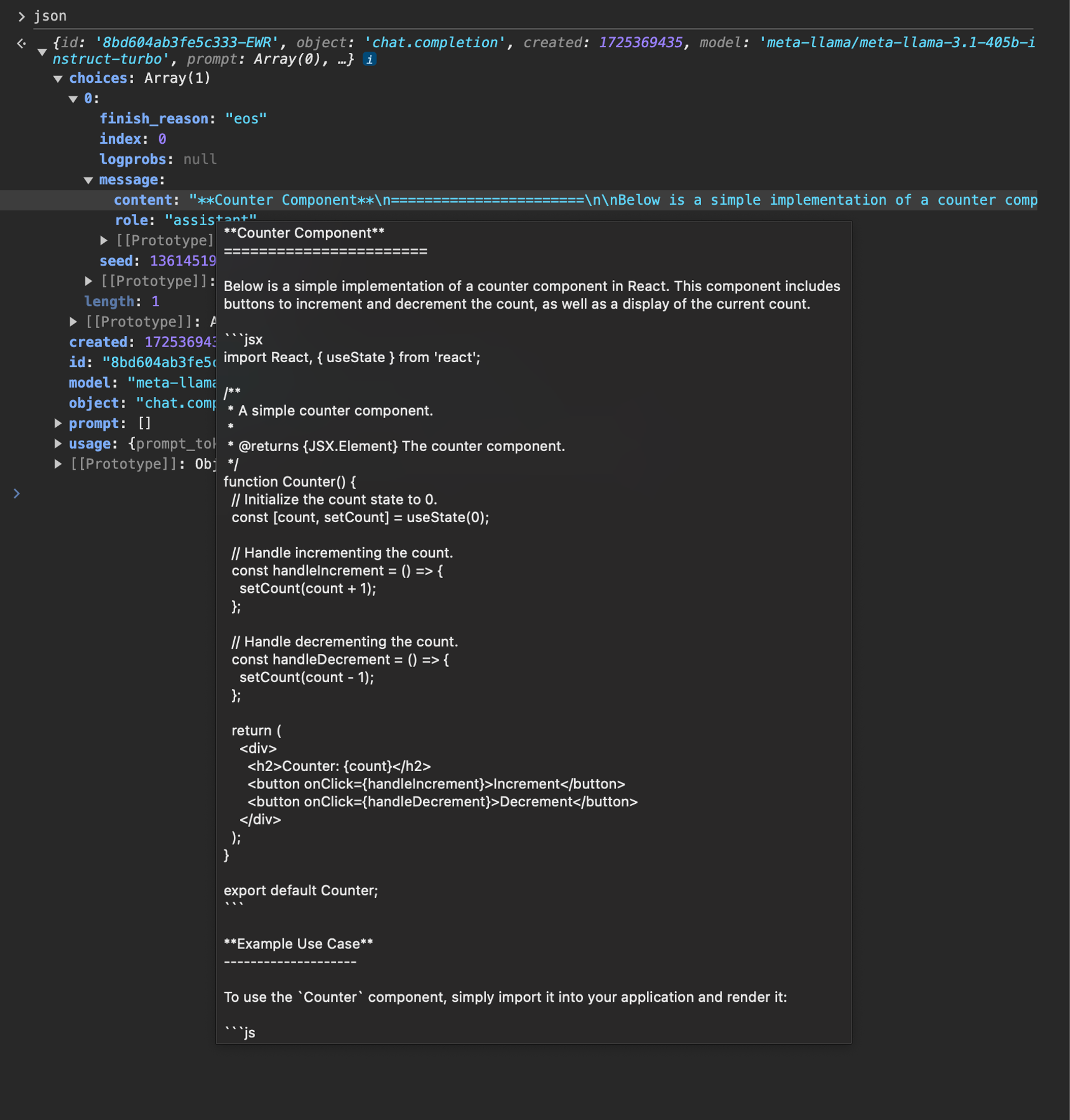
Engineering the system message to only return code
We spent some time tweaking the system message to make sure it output the best code possible – here’s what we ended up with for LlamaCoder:JSX
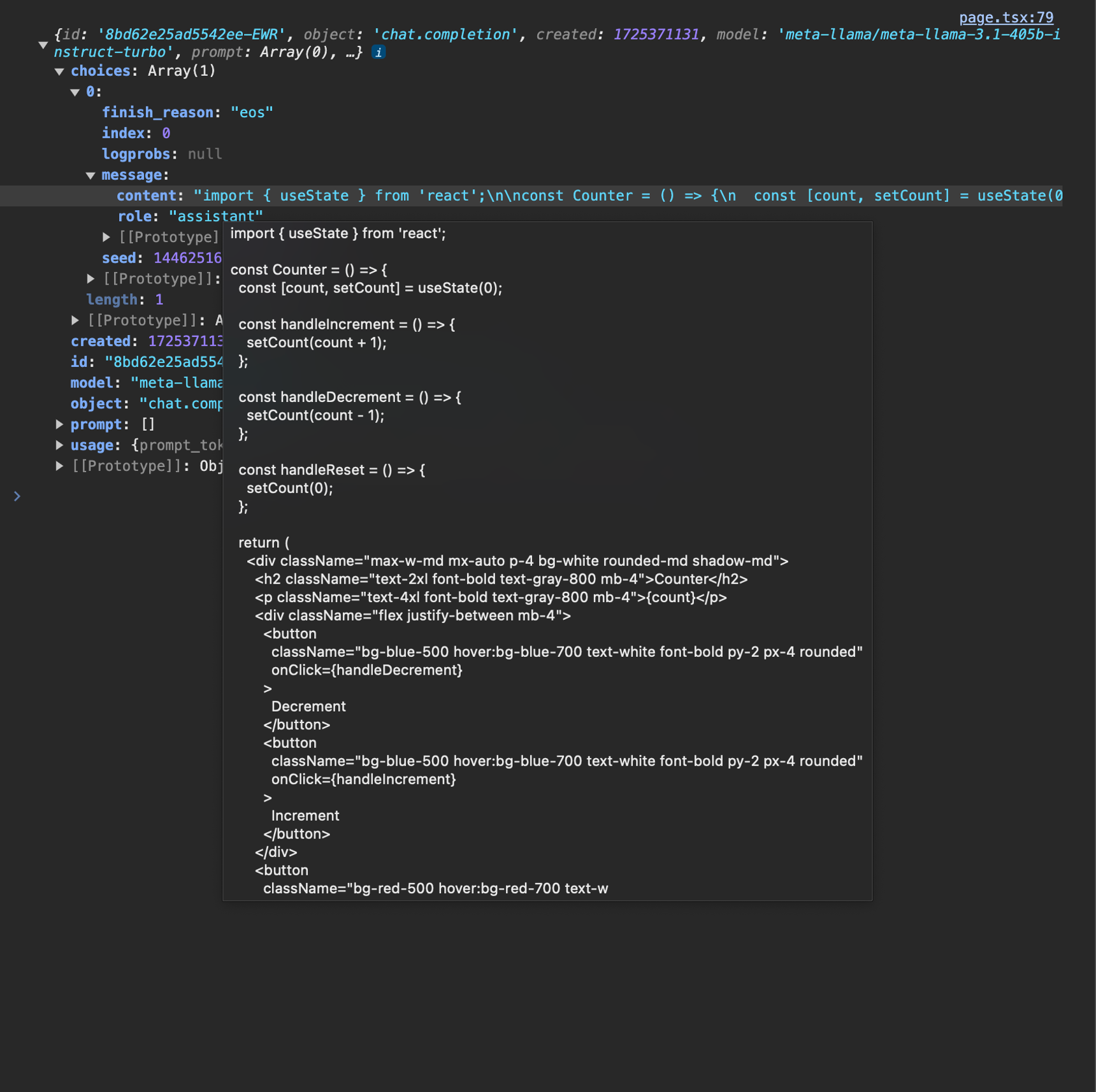
Running the generated code in the browser
Now that we’ve got a pure code response from our LLM, how can we actually execute it in the browser for our user? This is where the phenomenal Sandpack library comes in. Once we install it:Shell
<Sandpack> component to render and execute any code we want!
Let’s give it a shot with some hard-coded sample code:
JSX
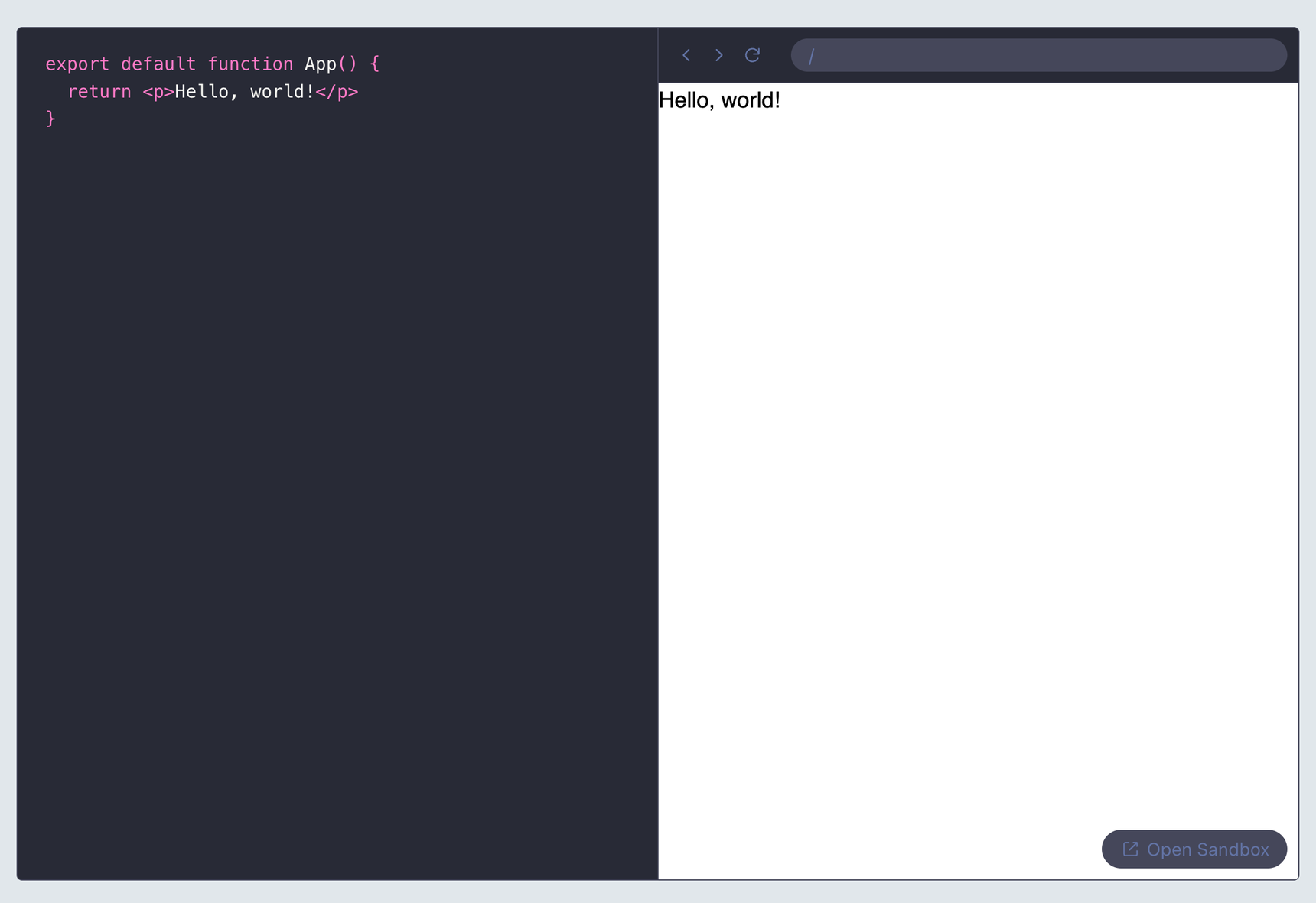
generatedCode:
JSX
generatedCode is not empty, we can render <Sandpack> and pass it in:
JSX
<Sandpack> renders our generated app!
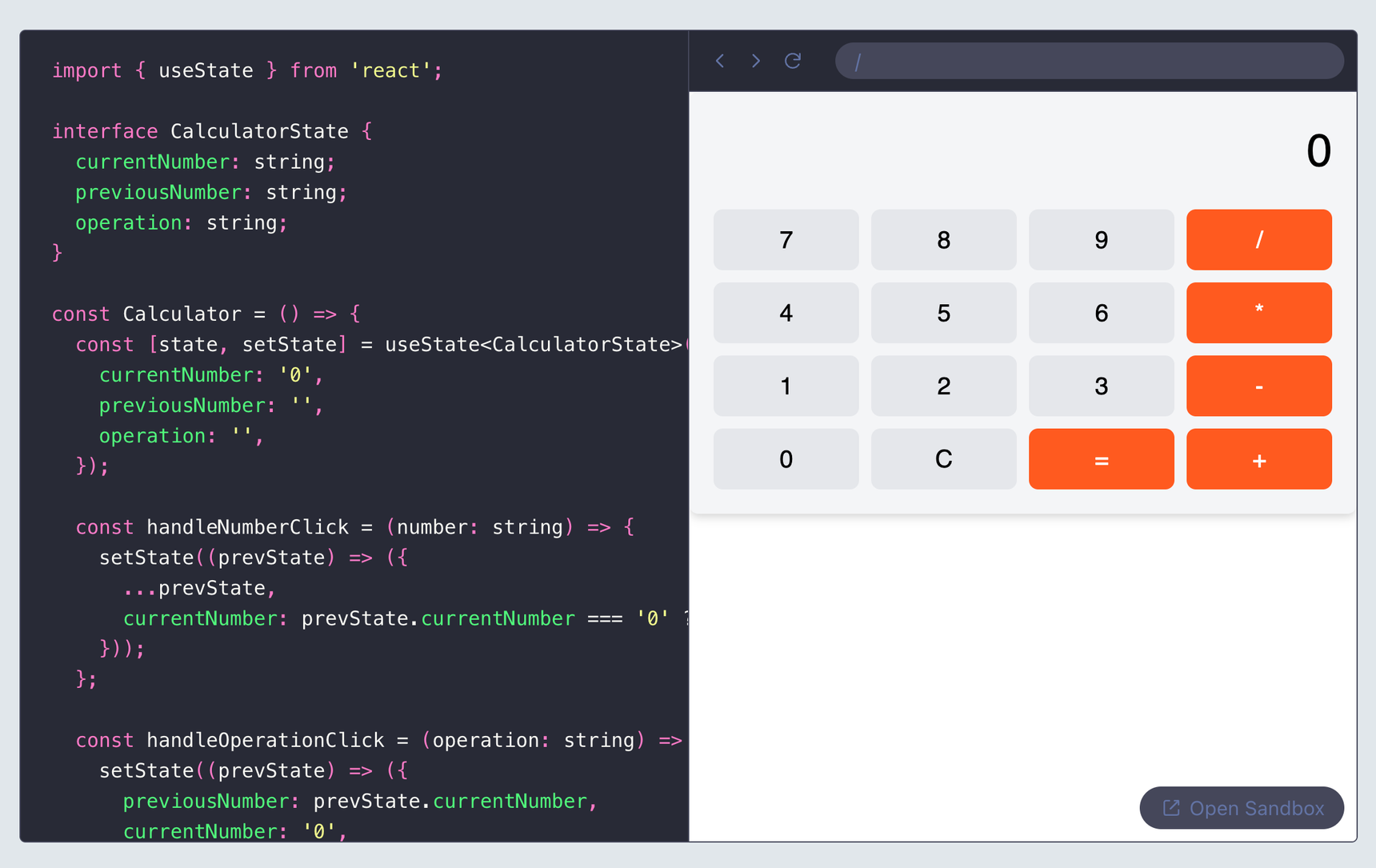
Streaming the code for immediate UI feedback
Our app is working well –but we’re not showing our user any feedback while the LLM is generating the code. This makes our app feel broken and unresponsive, especially for more complex prompts. To fix this, we can use Together AI’s support for streaming. With a streamed response, we can start displaying partial updates of the generated code as soon as the LLM responds with the first token. To enable streaming, there are two changes we need to make:- Update our API route to respond with a stream
- Update our React app to read the stream
stream: true option into together.chat.completions.create(). We also need to update our response to call res.toReadableStream(), which turns the raw Together stream into a newline-separated ReadableStream of JSON stringified values.
Here’s what that looks like:
JSX
JSX
res.json() it. We need a small helper function to read the text from the actual bytes that are being streamed over from our API route.
Here’s the helper function. It uses an AsyncGenerator to yield out each chunk of the stream as it comes over the network. It also uses a TextDecoder to turn the stream’s data from the type Uint8Array (which is the default type used by streams for their chunks, since it’s more efficient and streams have broad applications) into text, which we then parse into a JSON object.
So let’s copy this function to the bottom of our page:
JSX
createApp function to iterate over readStream(res.body):
JSX
for...of to iterate over each chunk right in our submit handler!
By setting generatedCode to the current text concatenated with the new chunk’s text, React automatically re-renders our app as the LLM’s response streams in, and we see <Sandpack> updating its UI as the generated app takes shape.